adventures in sandboxing
#author_luna #sandbox #claude_code #ai

image: generated with nai4.5full, with claude code opus 4.6's anime girl self image
I see my friends playing with fire.
this fire has a specific shape to it, one that wasn't known to us a year ago. it has many names: --yolo, --dangerously-skip-permissions, agentYoloMode, all of those carrying promises of great power for those who dare to summon it. my friends haven't been burned yet but I see what will, nay, must happen. if not to them, then to someone close in my graph, and they will all painfully learn the lesson together.
well, at least that's what I was thinking when I saw them use the flag and tell me that it's fun - but for me, one who wishes for her computer to not be obliterated by forces - forces that may not even be malicious in nature but just accidental... I just can't use it in good conscience.
so, let's talk about agent sandboxes, shall we?
the problem statement #
I can't give a good and proper introduction to Claude Code (CC) from the ground up, so if you're interested I would vouch for Steve Klabnik's intro articles.
since around the release of Claude Sonnet 4.5 in September, I have been increasingly using CC for various projects and side-projects and in the past few weeks, due to various reasons, I have started to put it in overdrive to discover where this kind of system fails. sometimes it does fail, sometimes I get extremely surprised, but I can see the bottleneck.
at various points in my general use of CC, I have found the following sequence of events happens often:
- I submit a prompt to CC in Plan mode
- CC creates a codebase exploration "subagent" (not relevant to sandboxing)
- the subagent wants to invoke GNU
find[^1] - since the operation of submitting a prompt into a plan is asynchronous, I do something else and sometimes look at the terminal
- I notice that it wanted to invoke
findand it looks good to me, so I approve it - a couple of seconds pass, Claude repeats step 3; sadly, I have already gone to another window because I'm not going to wait for multiple network requests to Anthropic's compute
- after a while, a plan appears from the silicon machine into my eyes
- I hash out a plan that makes sense to me
- I select the "Yes, clear context and auto-accept edits" option and it runs
- repeat step 3 with a different command. maybe instead of
findit'spython3, orgo run, etc (except instead of going back to plan mode, it's in the development loop)
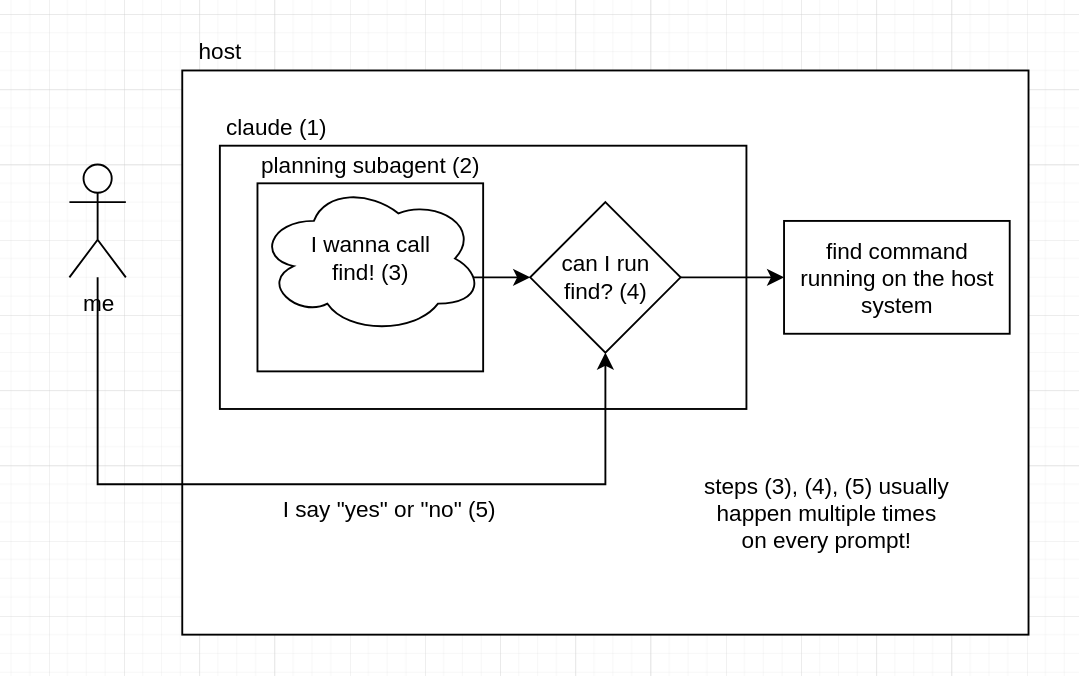
when a harness like CC gets a request from Claude to run a command, I can select the following options:
- "Yes", which accepts and runs the current wanted invocation (e.g
find myrepo -type f -iname '*Module.py*') - "Yes, and don't ask again for (command) commands in (folder)", which as it says will let the harness skip user verification for the given command
- "No", which would let me talk to the agent to then give better instructions on what to run or or what to do.
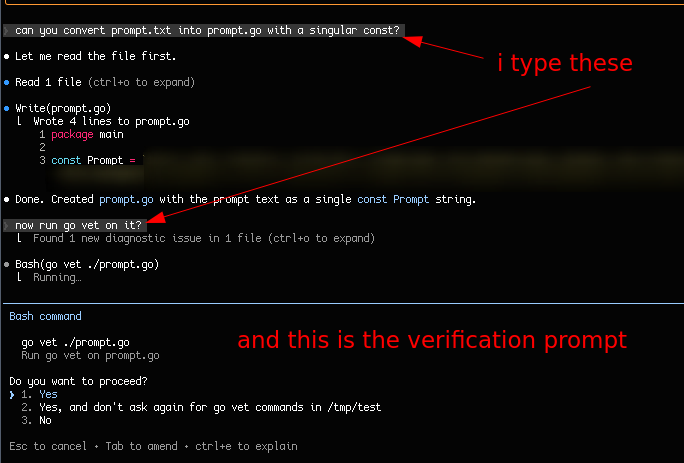
the number of these types of verification events is worrying to me for three reasons:
- verification fatigue means that after a while I'll just accept without thinking. it may be fine once, but once the behaviour is established, it would only take one incorrect invocation to do massive damage.
- selecting "yes, and don't ask again for (command)" relies on CC's detection of which part of the command is common, and which part varies between invocations
- for
go vet <path>, it can confidently say path is the variant so it can ask me if I want allgo vetto be auto-allowed - for
findthough... it's not clear unless you effectively hardcode the spec into the harness to find out a safe subset. because of this, allowingfindmeans allowingfind -exec "<any command>"and while CC/other harnesses can hardcode that fact, there may be more commands with such functionality that would be unacceptable to allow
- for
- it burns my daily/weekly usage limits because of the asynchrony (IIRC Claude's cache runs for ~5 minutes, maybe it's longer when running in CC - but it means if I do something else and don't check in every 5 minutes at most, I'm going to run inference on "fresh" context which uses more "credits"). so preferably I want to keep CC running for as much as it can autonomously
one of the answers to the verification problem is the aforementioned "yolo mode". in this mode, the agent harness (Claude Code, Codex, Gemini CLI, etc) will let the LLM invoke any commands on the host system without any verification by the user of the harness. depending on the amount of trust that you have in the harness/LLM/agent, this may be fine for you, but it's sadly not for me.
at its core, a system like this is something that is not me (even if I am using it while in my cognition loop to write code, it does not live 24/7 through my experiences, I remain the primary actor for my primary self): it should not perceive information that I didn't give it. from this premise, I treat the harness as a conversation partner, giving them the ability to poke through every single neuron of mine would be a massive invasion of privacy (I'm sure Anthropic has good data policies to prevent this from ever becoming an issue, but the fact that data that is important to me is sent out into the internet at large, even if encrypted, is a bad thing)
the solutions #
so, I'm working from the following principles:
- running an agent for as long as possible is a good thing
- I don't like doing verification for mundane things like
find, but I know allowingfind(or any other command with privilege escalation ("privesc" capabilities) likefind) is asking for trouble - I still want to run yolo mode
that's where sandboxes come in, and we have a lot - a lot - of new sandboxing scripts and tech coming to try to keep these agents under control. in the past week, I have noticed at least 3 to 4 new products/projects for this fly by my eyes, as everyone else also wants a way to run yolo mode safely.
wait, doesn't claude code have a sandbox? #
yes it does! but here's what it does when you set it up on the default settings (not talking about customizing it, who wants to do that??):
- when Claude wants to run a command, it runs by default on a sandboxed environment where your filesystem is read-only, save for the project folder which is read-write
- the command, if it needs RW outside, fails. Claude notices it and submits the command again but without the sandbox
- this then prompts the usual verification flow and we're back on the same loop.
it's better than nothing but because of these reasons, claude's /sandbox is just not enough for what I need.
remote sandboxing #
sprites by fly.io #
![]()
the idea with sprites is that they spin up a souped-up VPS (the implementation details of which do not really matter) and you ssh to it and can run your harness inside.
in regards to my feelings on it:
- the sprites CLI and general networking model are absurdly confusing to me; I haven't been able to proxy
iperf3between the VPS and my host machine to figure out how much bandwidth and latency I actually have. no port forwarding actually works (and it just binds automatically regardless? very confusing) - because it's remote, it probably runs far away with >100ms latency, AKA it only works in the USA.
exe.dev #

the idea with exe.dev is that they spin up a souped-up VPS (the implementation details of which do not really matter) and you ssh to it and can run your harness inside.
I think they have a custom agent harness inside the VPS so that you can dictate commands to it.
feelings:
- they are mischievous because even though their pricing page says there's a trial ("every new account automatically runs on a free trial with full Individual plan access"), once you try to sign up, you're redirected to a Stripe page asking for credit card for a 20USD purchase. hell nah, be honest (it could be a pre-auth, but I'm not going to play with someone that's not being clear enough, it's either a free trial or it isn't).
- I assume that their VMs also run in the USA, and I would have a bad experience trying to type into CC from it.
shellbox #

the idea with shellbox is that they spin up a souped-up VPS (the implementation details of which do not really matter) and you ssh to it and can run your harness inside.
compared to sprites and exe.dev, shellbox's UI runs purely inside SSH, your account is your SSH public key
feelings:
- pinging
shellbox.devshows a direct hetzner IP - this feels like, to me, that it's just someone with a hetzner dedi selling space on it for 10USD (10USD is the minimum amount! lol!), I can get a somewhat usable hetzner VPS for 4EUR (4.72USD on 2026-02-07) a month, set it up for free, and I'd have the same latency problems as the other two
in my research, I saw a post which also goes through each of the remote services mentioned and actually tries to use them beyond what I did here. it is a nice addition to this article and I recommend it: https://lalitm.com/trying-sprites-exedev-shellbox/
for all three, the common denominator issue is that they're remote. a remote system, far away from where I live, means that each keystroke will be subject to a lot of extra milliseconds - and that is unacceptable UX to me.
well then, what about local tools, things that run in my computer?
local sandboxing #
there are all sorts of local tools or scripts that do local sandboxing, so I'll have to categorize them by their core isolation primitive:
- syscall restriction (seccomp bpf, landlock. cosmopolitan pledge, lukehinds/nono)
- process isolation (linux namespaces, docker, bubblewrap. lxroot, sandbox-run)
- full VMs (vagrant, qemu.)
plus there's a bunch of mac-only tooling that i'm simply disregarding as "can't run it".
the problem with the first two is a question of philosophy, going back to a previous paragraph: I see the agent coding loop as a conversation partner that gets to be treated as a different being than mine. this is not arguing that a coding agent is sentient or not because it doesn't matter, I just want to treat it with the same respect I want to be treated with. static sandboxes at the wrong level of abstraction (in my opinion) lead to more effort spent in the conversation itself:
- either from the mental effort to know which of the thousands of executable binaries can wreck the system
- from the technical effort of changing the sandbox and having to restart the agent under the new policy
- the agent's raw effort in not understanding that it's in a sandbox, attempting multiple things with each error, only for it to eventually figure out that it is in a sandbox and give up on the task
from those axioms the following requirements appear:
- sandboxes shouldn't restrict the CLI, but restrict the I/O interface (filesystem and network), because the available vocabulary can be very small.
- sandboxes should change at runtime to prevent having to restart the world every time.
- the agent should be able to request changes to the runtime!
the third one is I think where no other current tool has explored enough. I don't classify it as letting the agent privesc itself because any kind of policy change would have to be approved by me, the user of the system. I classify my computer as a second brain so it is of paramount importance that I am the one making the final decisions. the agent can justify its case though! as a practical example: $GOPATH may not be needed on my personal projects but would be wanted if there are private repositories that I can only access via proper git credentials. this is, by default, a more nuanced decision than "allow GOPATH always" / "deny GOPATH always"
with this in mind, I review the solutions:
- while I was able to set up a proof of concept for seccomp bpf that let a separate daemon in userspace make filesystem decisions, I was also able to consistently lock my kernel's fs ops, outside of the sandbox - so I'm classifying the whole thing as too unstable.
- landlock can't do a dynamic runtime policy AFAIK, so can't use it
- for linux ns/docker there is Something(tm) you can do. this was presented to me by one of my friends, emma as if it was some kind of illegal scripture; I now share this with you: https://jpetazzo.github.io/2015/01/13/docker-mount-dynamic-volumes/
- (due to how cursed and illegal this is, I haven't chosen this option)
- for bwrap, requires restart, can't do
- this effectively leaves VMs as the most flexible isolation primitive to build something on top.
drawbacks with VMs:
- massive build costs (you need to get a kernel, separate root fs, etc)
- networking is not straightforward
- filesystem sharing between host and guest has to be done through a protocol both kernels know about
- hardware cost is greater than just having a separate process since you have a whole kernel loaded in RAM.
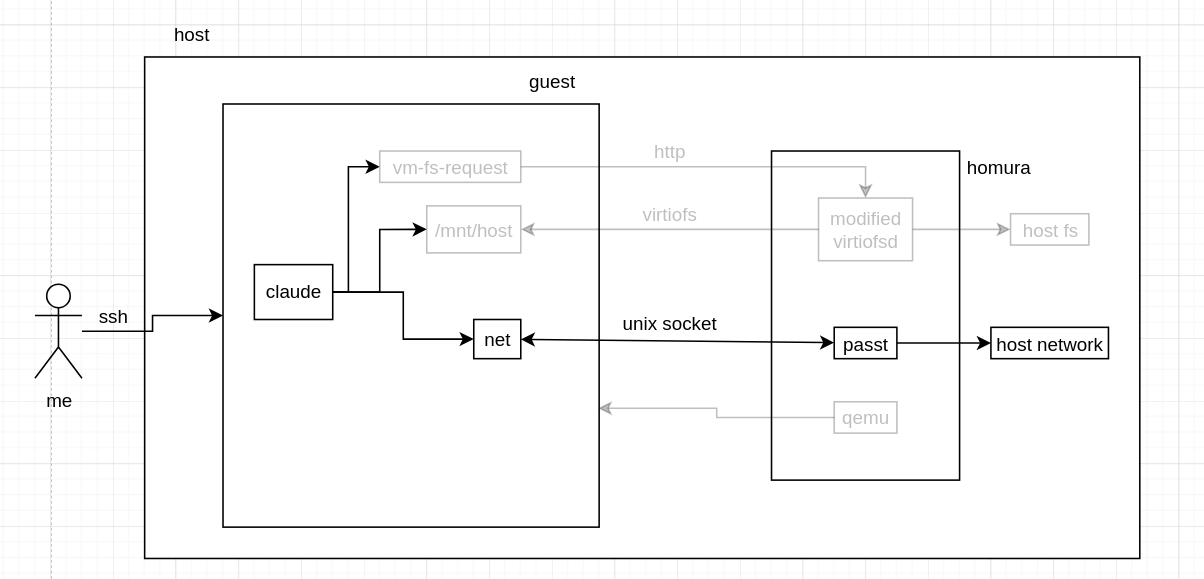
homura #
with those things in mind, I built my own tool, homura. by default, there's no isolation: it started out as a CLI tool to help me easily create worktrees, as I was turned off by the CC-on-web product[^2]. after falling down the sandboxing hole, however, I built homura vm, which can spin up an Alpine VM with QEMU in ~5 seconds on my machine, networking and filesystem sharing configured, and with just claude and go[^3] installed.
homura isolation model #
it's qemu with KVM, nothing too out of the ordinary there. the VM image is constructed from the Alpine Linux kernel-virt plus some specific kernel modules to bring virtio support, networking, namespaces (for docker), etc. in theory, it can be any distro using that kernel: the rootfs is built separately with docker running on the host, and then the container is dumped to /tmp, and mke2fs builds an ext4 image (the image is around 2GB on disk, and then is sparse-extended to 10GB on VM startup).
homura filesystem model #
this is the primary focus of the sandbox and is the one I ran the most experiments on[^4]. the goals for this are:
- mirror the minimum amount of paths needed to make
claudework - let the agent expand its list of mirrored paths after verification with operator
at the start, I decided to try the 9p protocol as the primary method of sharing the filesystem. the guest would use the 9p kernel driver, and then I would have a custom 9p server, whose job would be to:
- passthrough requests from the guest to the host filesystem on allowed paths
- have a path exposure policy that would let operations succeed only on allowed paths (as well as listing files that are allowed, etc)
- have an HTTP "Control API" that would let both the VM request new paths (with auth) and for me to permit path requests for the engine (using different auth)
- the VM accesses the Control API via a CLI that is added into the VM image
- each homura VM gets an access token that can only access the "request path" API. this is done by passing the token into the kernel cmdline, and then scripts inside the VM read
/proc/cmdlineto extract the token and other bootstrap parameters (like host home path, API ports, etc)
... and then I tried using SQLite, which didn't work because of mmap()[^5]. lol
after that, I attempted to build my own 9p implementation with FUSE (instead of relying on the 9p kernel driver). in theory, that would let me have mmap() while still backing the filesystem with 9p itself (accepting the tradeoff that the host wouldn't be able to properly access the sqlite files until VM shutdown). this worked (even w/ sqlite), but once I started working on another project (in Elixir) that compiled into the project directory, the compile times were absurdly slow when compared to the host. turns out that it's just not performant enough for real work. even CC itself was slow.
through some more research, I stumbled upon virtiofs - effectively a FUSE-to-virtio bridge - and which is absurdly fast relative to 9p. it is better explained in this FOSDEM 2020 talk. the default implementation of virtiofs is virtiofsd but it doesn't support dynamic policy ootb. I forked it and asked Claude to write a filtered passthrough with Control API; the results are here.
after all this, this is the current architecture for how the filesystem works. important CC paths like ~/.claude get linked from /mnt/host/home/<user>/.claude into the VM's /root/.claude (the modified virtiofsd ensures that the files made by the VM which are by root are ultimately owned by my non-root user in the host).
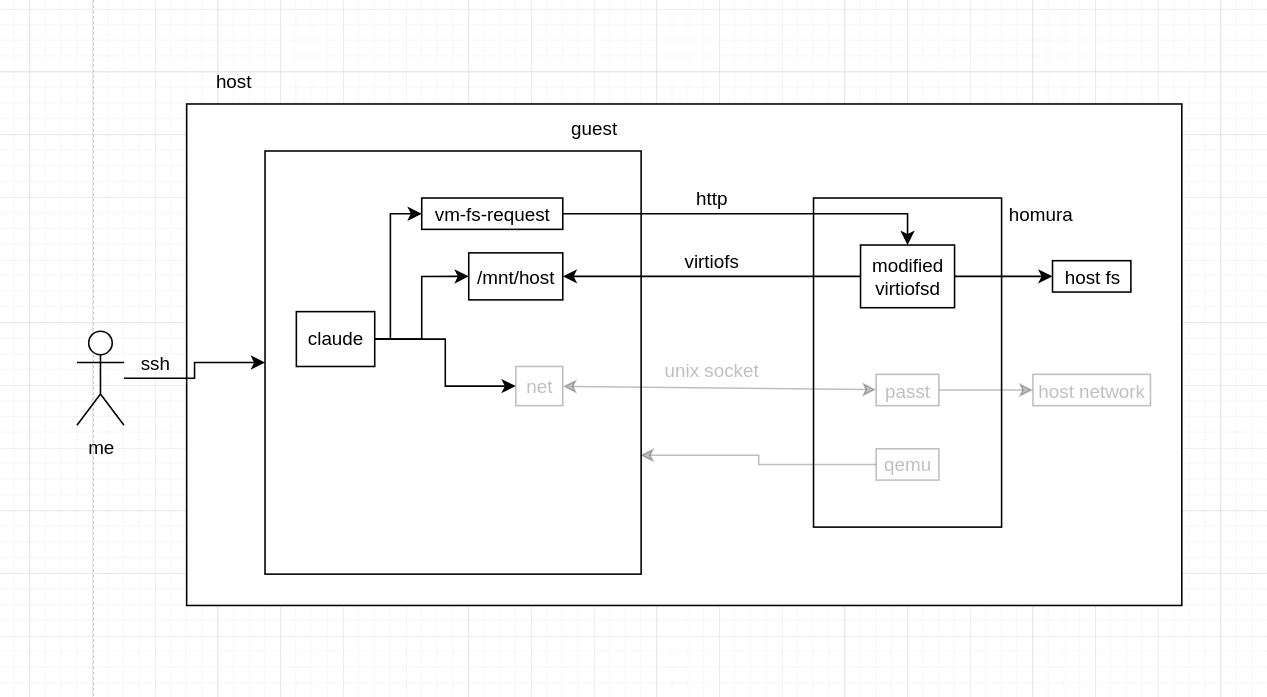
homura network model #
the network model is hopefully more straightforward than sprites. each VM gets 10 ports mirrored through passt with the first port already taken by the ssh server; synchronization of those ports is done via kernel argument injection so that the VM knows where to start sshd.
I think I can polish this a bit to be more dynamic, and restrict to a known-good set of hosts (like pypi, hex.pm, npm, github, etc) but as said before, the filesystem was the primary focus. luckily, I can change the network model without breaking the fs (as long as the guest can access the necessary ports for the Control API which runs on the host).
conclusion #
is homura useful to you? I don't know, probably not. I needed a sandbox that matched my freak, so I made one.
sidenotes #
[^1]: I haven't seen Claude's find usage break down on my work macbook without GNU find, but let's not go into a side-tangent here, there's many to have
[^2]: it felt so much slower than having the harness on my machine, it's impossible to install basic Elixir tooling, and the requirement that I need to PR on github to even see the work that claude did are all major turnoffs for the entire product. I'm sure it's good for some people (and it may be useful to me if I'm on the run/away from my machine), but for daily-driving, it just doesn't fit me.
[^3]: this works because both (1) I install claude on the default image and (2) homura shares the ~/.claude directory as read-write by default, as well as the project directory (also read-write).
[^4]: in the claude sandbox docs, they say the following: "Effective sandboxing requires both filesystem and network isolation.". I agree with this, but for anything to even work, I need good mechanics for the filesystem itself. network sandboxing can be done as an added layer on top of the core architecture, I may be able to use matchlock for this!
[^5]: Claude was able to figure it out, and placed its sqlite files on the VM's /tmp to make it work. that was a cool experience to see, but I want everything to be in the project files I work with
credits #
this article came with help from:
- philpax for a lot of english vibe-checking
- emma, natalie, karashiiro for proof-reading