llama3 inference numbers
#llama #large_language_models #technology #performance
timeline:
- started project
%at=2024-04-20T00:16:05.592Z - finished this version
%at=2024-05-19T22:20:38.907Z
to continue the tradition from llama inference numbers and llama2 inference numbers, mixtral inference numbers, here are the llama3 numbers. this time i made a script: llamabench to scale out to more machines and ensure my data is correct across all of them
all benches running with llama.cpp commit 0e4802b2ecbaab04b4f829fde4a3096ca19c84b5 (2024-04-19)
model used: https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct-GGUF/tree/main, at Q4_K_M quantization across all machines
reading recommentation #
there is a LOT of data. i recommend skipping to the findings. they provide pretty graphs.
inference hardware #
many thanks to people that provided hardware systems to run the benchmarking script
- the akaris'
switchblade, arctic-rose, sidekick, apparition, obstinate-serenity - utsuhorocks'
fusion - cynthia's
DESKTOP-T0IEVSO - ena's
steamdeck
| hostname | cpu | ram | gpu |
|---|---|---|---|
| wall | AMD Ryzen 5 5800X3D | 32GB (4x8) DDR4-2666 | NVIDIA GALAX RTX3060 12GB |
| elpis | AMD Ryzen 5 4600G | 16GB (1x16) DDR4-2666 | AMD MAXSUN RX580 2048SP |
| switchblade (steam deck lcd) | Zen 2 4c/8t, 2.4-3.5GHz (up to 448 GFlops FP32) | 16 GB LPDDR5 on-board RAM (5500 MT/s quad 32-bit channels) | N/A |
| steamdeck (also an lcd edition) | - | - | - |
| chlorine (steam deck oled) | Zen 2 4c/8t, 2.4-3.5GHz (up to 448 GFlops FP32) | 16 GB LPDDR5 on-board RAM (6400 MT/s quad 32-bit channels) | N/A |
| arctic-rose | Intel Xeon E5-2667 v2 | 32GB (4x8) DDR3-1866 ECC | NVIDIA MSI RTX2060 12GB |
| fusion | Intel(R) Core(TM) i7-4770 CPU @ 3.40GHz | 32GB (4x8) DDR3-1600 | N/A |
| DESKTOP-T0IEVSO | AMD Ryzen 7 3700X | 32GB (2x16) DDR4-1800 | N/A |
| sidekick | Intel Core i5-2400 | 16GB (4x4) DDR3-1600 | N/A |
| apparition | Intel Xeon E5345 (x2) | 12GB ??? DDR2-??? (need to open it up and check) | N/A |
| obstinate-serenity | Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz | 8GB (2x4) DDR3L-1600 | N/A |
| reticent-iris | Intel Core i7-4770 | 12GB (3x4) DDR3-1600 | N/A |
| ubuntu-8gb-hel1-1 | Hetzner CX31 (2 "shared" vcpu) | 8GB RAM (QEMU) | N/A |
| ubuntu-8gb-hel1-2 | Hetzner CCX13 (2 "dedicated" vcpu) | 8GB RAM (QEMU) | N/A |
| scw-beautiful-hertz | Scaleway DEV1-L (4vcpu) | 8GB RAM (QEMU) | N/A |
inference software #
| hostname | distro | version | kernel version | gcc | nvidia driver | openblas |
|---|---|---|---|---|---|---|
| wall | void linux | n/a (rolling release) | 6.6.22_1 | 11.2 | 550.67 | 0.3.27 |
| elpis | void linux | n/a (rolling release) | 6.6.22_1 | 13.2 | n/a | 0.3.26 |
| switchblade | steamos | beta 3.5.17 + gentoo prefix | 6.1.52-valve16-1-neptune-61 | 13.2.1 | n/a | 0.3.25 |
| chlorine | steamos | 3.5.19 + gentoo prefix | 6.1.52-valve16-1-neptune-61 | 13.2.1 | n/a | 0.3.25 |
| steamdeck | steamos | 3.5.7 | 6.1.52-valve9-1-neptune-61 | 13.1.1 | n/a | 0.3.23 |
| arctic-rose (unstable sw atm) | gentoo | n/a (rolling) | 6.6.28-gentoo-myriad | 13.2.1 | 550.78 | 0.3.25 |
| fusion | debian | 11 | 5.10.0-20-amd64 | 10.2.1 | n/a | 0.3.13 |
| DESKTOP-T0IEVSO | windows | 10 22H2 + MSYS2 2024-01-13 | n/a | 13.2.0 | (amd) 24.3.1 | 0.3.27 |
| ubuntu-8gb-hel1-1 | ubuntu | 24.04 noble | 6.8.0-31-generic | 13.2.0 | n/a | 0.3.26 |
| ubuntu-8gb-hel1-2 | ubuntu | 24.04 noble | 6.8.0-31-generic | 13.2.0 | n/a | 0.3.26 |
| scw-beautiful-hertz | ubuntu | 22.04 jammy | 5.15.0-102-generic | 11.4.0 | n/a | 0.3.20 |
notes #
- amd gpu devices running with amdgpu kernel driver
- some machines have
-v2on them. some data had to be redone for the machines due to methodological/interesting software update reasons
the graphs #
cpu graphs #
the "clean" style means it ran without any BLAS libraries, just raw gcc
there are various categories of compute we will look into with later graphs
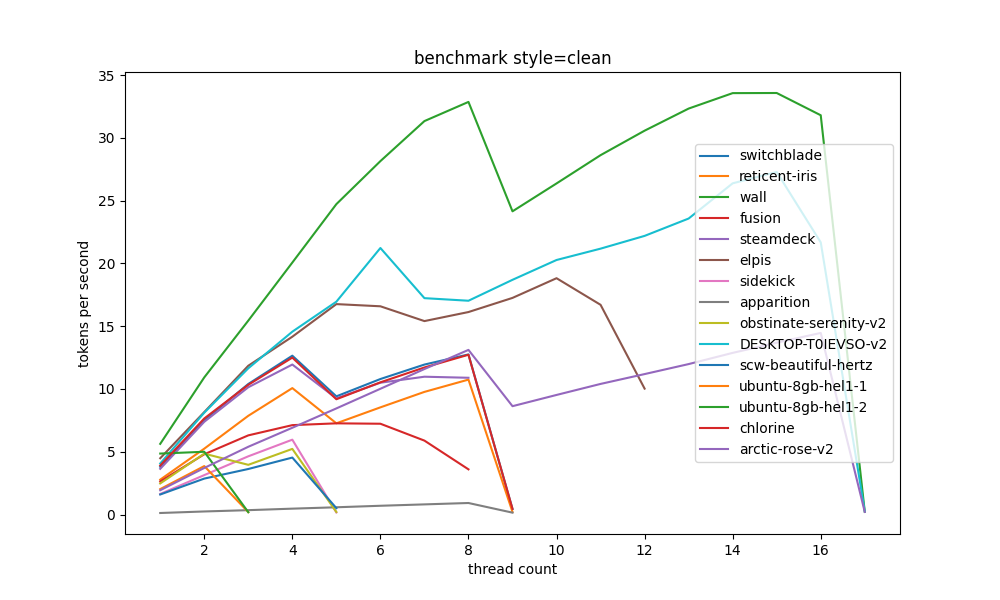
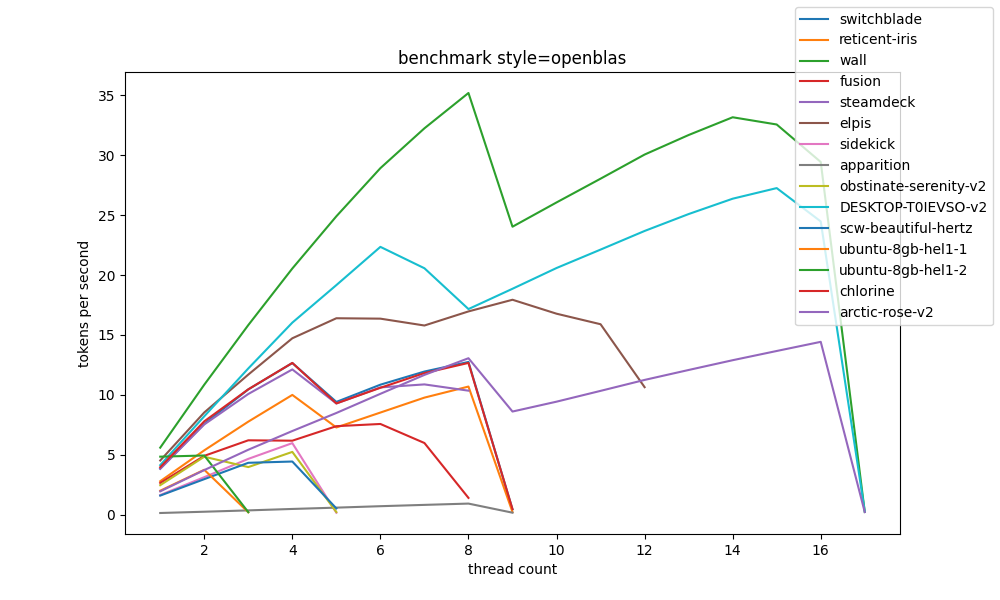
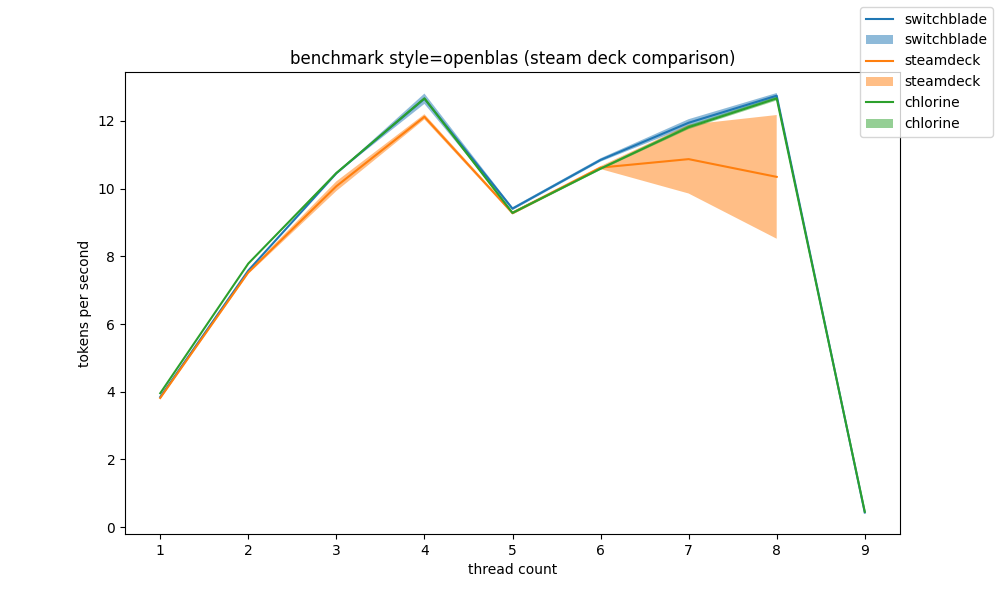
openblas #
the first interesting comparison we can make is how much openblas actually contributes to a system, and in general the results are somewhat inconclusive. +2t/s at best.
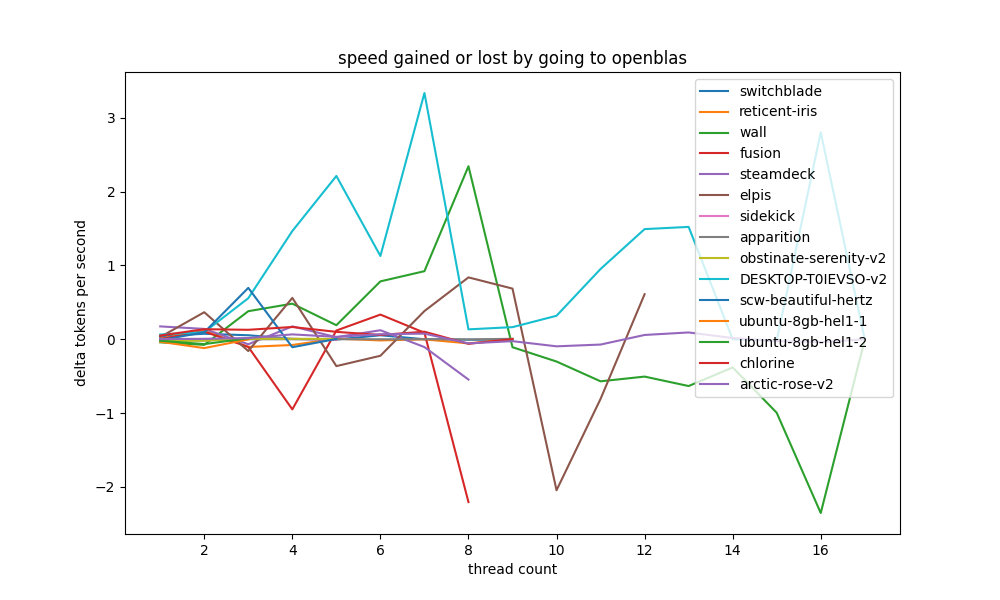
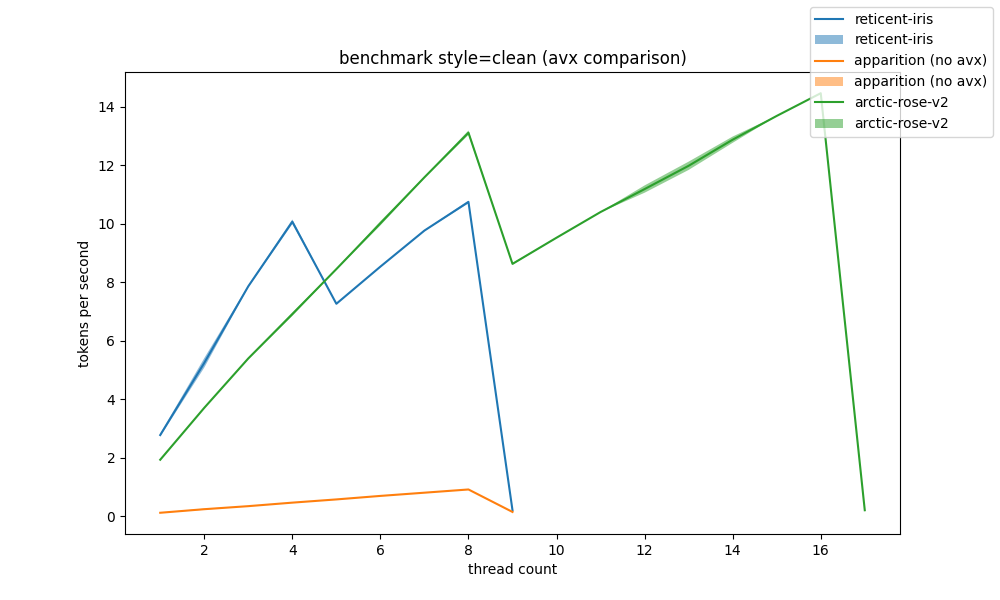
avx #
one question we had while going through the data is what avx can do in terms of inference speed. while we don't have a system with avx and another without that is of comparable specs, we have two systems that are "close enough":
- apparition:
n_threads = 1 / 8 | AVX = 0 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 0 | ARM_FMA = 0 | F16C = 0 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | - arctic-rose:
n_threads = 1 / 16 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | - reticent-iris:
n_threads = 1 / 8 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
primary differences between apparition and arctic-rose:
- ram: from DDR2-667 to DDR3-1866 (by raw numbers, a 10x improvement in ram clock rate)
- cpu: Xeon E5345 -> Xeon E5-2667
- 65 nm -> 32 nm
- Q1'07 -> Q1'12 (5 years difference)
- 2.33 GHz -> 2.90 GHz
- 8 MB L2 Cache -> 15 MB Intel® Smart Cache
- whatever "smart" is
- 80 W TDP -> 130 W TDP
while the comparison can't be clear on avx vs. no avx, those changes in the system bring a massive improvement to inference speed (from basically 0.5t/s up to 10t/s).
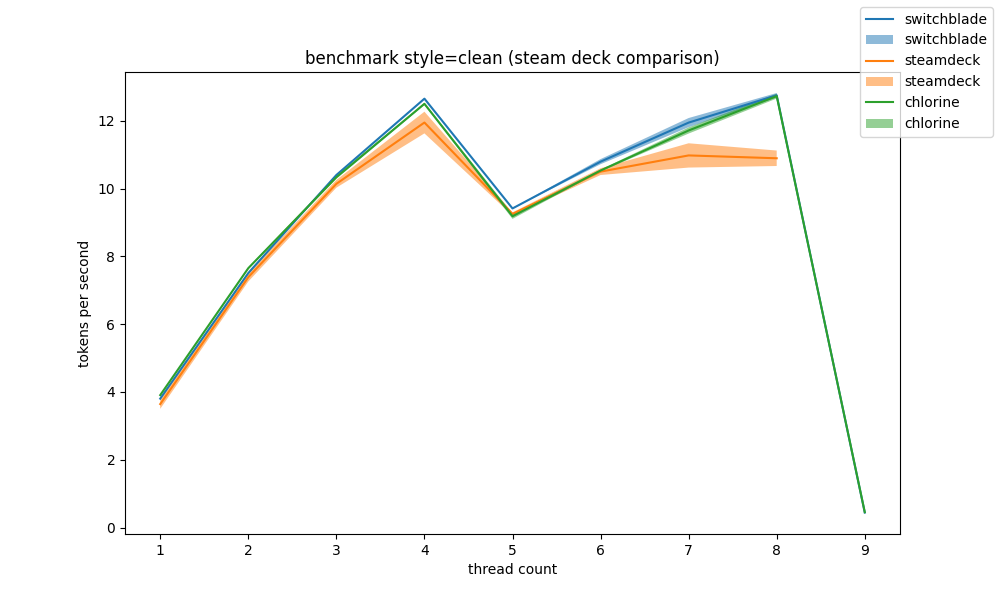
steam deck lcd vs oled #
it is known that the deck oled made an upgrade to its SoC that can bring up to 10FPS uplift depending on the game, as shown by GamersNexus' data
what about inference speed? actually not much. (chlorine is an oled model, the others are lcd)
future work should look into running the vulkan backend on those devices. we were unable to get all the sdk's working right to build llama.cpp with it.
(note, steamdeck was likely not running with the cpu scaling governor set to performance, which is the likely reason its numbers do not align as well as switchblade, which also is a steam deck lcd)
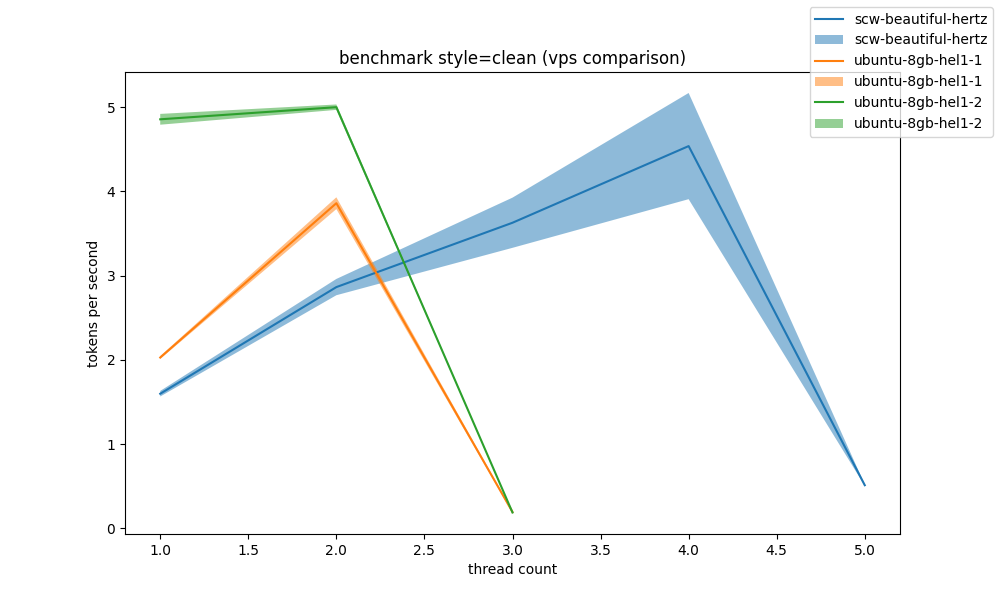
what about vps'es? #
the primary point in ggml's manifesto reads:
Inference at the edge
well, what about the cheapest edge we have? random vps'es from some of the cheap cloud providers?
at most, 5t/s, with a dedicated hetz getting the best per-thread speed (of course, because they're a dedicated vcpu, though i'm not sure if they area actually allocated to real hardware cores, rather than shared. looks like it from the data, at least)
also be aware that cpu scaling governors are also not performance as those cpus are QEMU virtualized, so i am unable to set them.
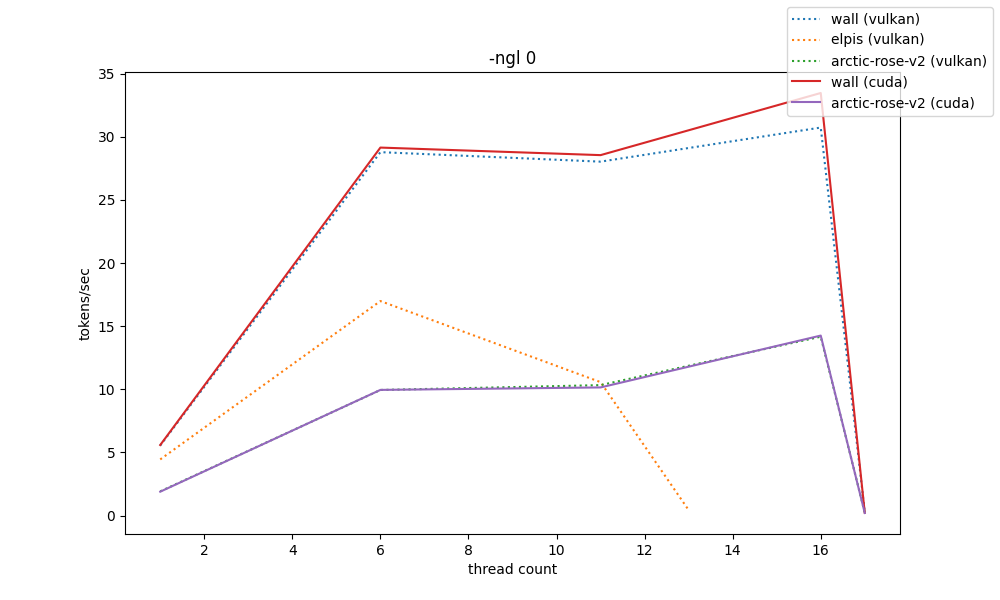
gpu graphs #
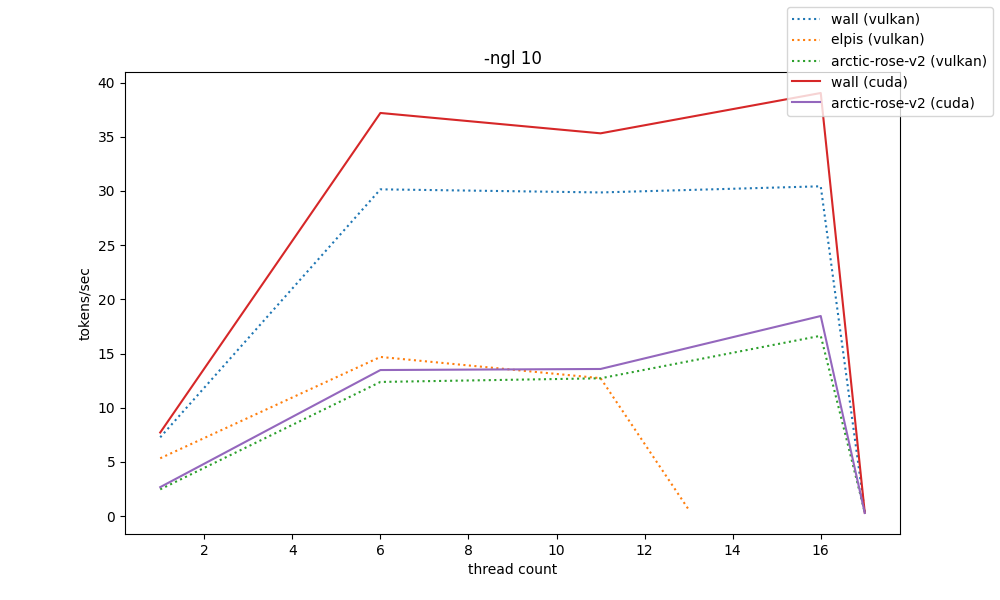
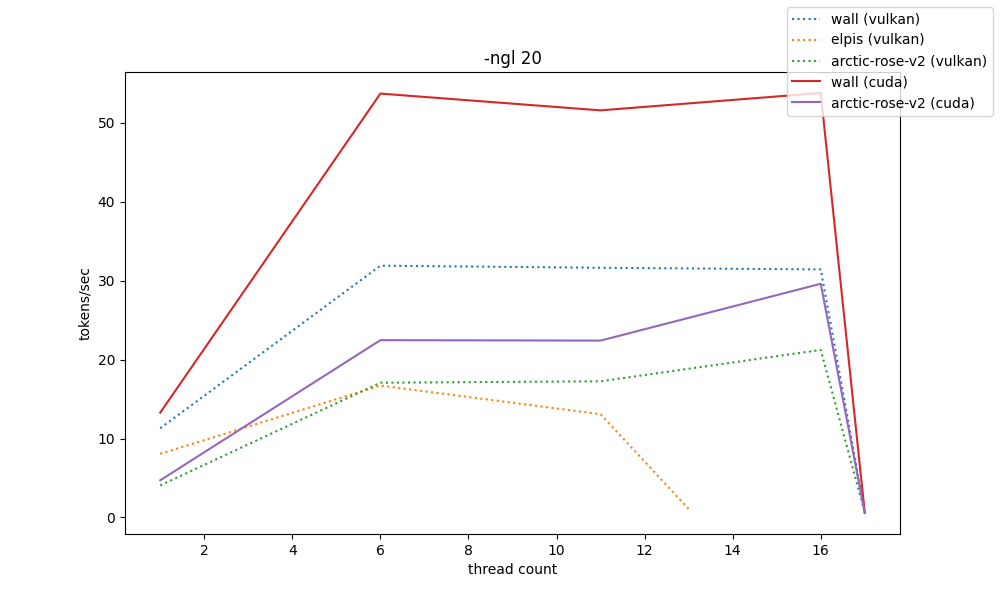
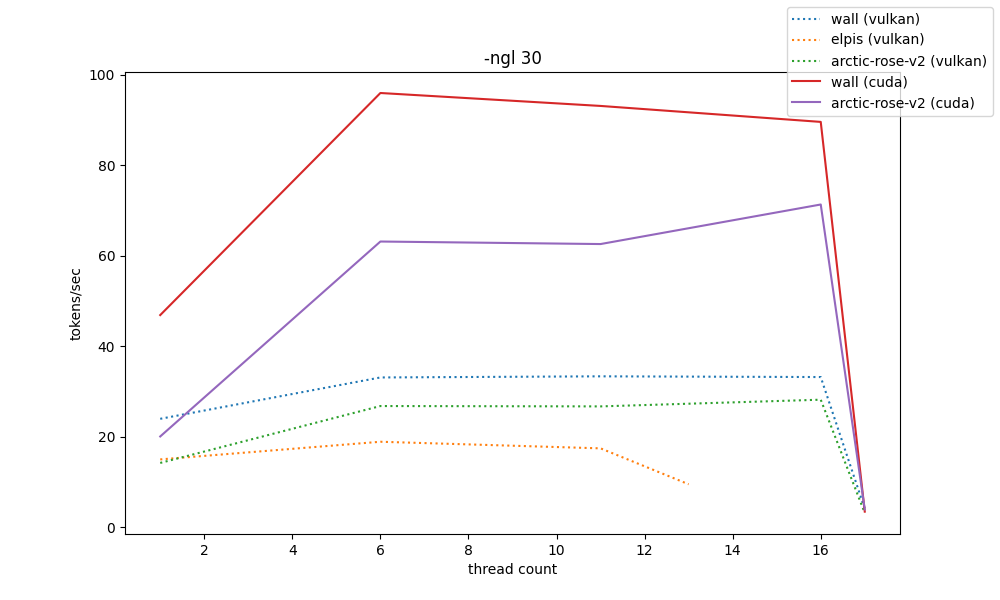
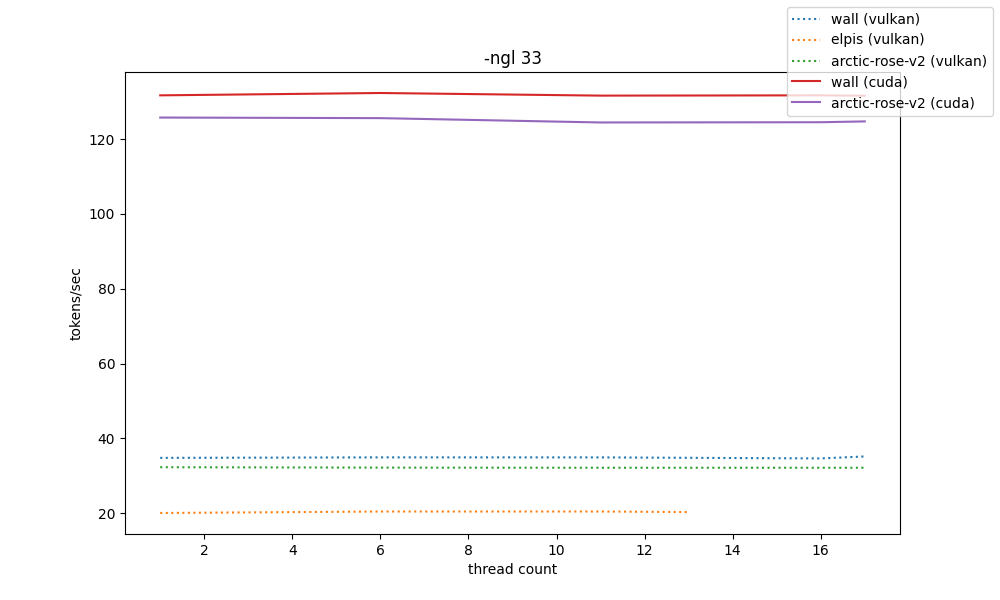
for gpu benchmarks, the -t and -ngl parameter spaces were greatly reduced so that benchmarks don't take days to finish. because of that, their resolution is decreased
the way these are shown is by showing 5 graphs at different scales of -ngl, from 0 to 33 (max). only two systems have nvidia gpus and so they can have both vulkan and cuda comparisons.
by the shown data, the llama.cpp cuda backend can provide absurd amounts of speed compared to vulkan, even though they operate almost the same at -ngl 0. heavily consider it even if finding a way to build it is a mess (hehe my python packaging patterns)
and elpis's RX580-2048SP-that-came-from-aliexpress-which-is-probably-downclocked can at best pull off 20t/s, which is somewhat surprising considering it's a 600BRL card (wall's RTX3060 pulls approx. 35t/s on vulkan, and that's running for around 2000BRL)
link to the raw data #
structured as tsv because of raw_timings column
raw_timings column is structured as json which is a list containing 5 lists (because each benchmark setting is ran 5 times for averaging) of 3 elements extracted from llama.cpp output:
- "sample ms per token"
- "prompt eval ms per token"
- "eval ms per token"
i don't actually know what those mean, so i took the number that sounded the most correct (eval ms per token), and did 1000/eval_ms_per_token to derive tokens/second speed.
if that's incorrect, feel free to suggest something and i'll rebuild the data (i don't think the findings would change that much from it, but it'd be good to have it correct for a possible llama4 release... you'll do it, right zuck? you'll release it to the mortals below you?)
https://raw.githubusercontent.com/lun-4/llamabench/mistress/llama3_luna_data.tsv