why all linear layers?
#author_luna #artificial_intelligence #large_language_models #fine_tuning #peft
tldr "because it didn't work with just the original lora layers", i dont know the exact reasons why
https://f.l4.pm/notice/AXriEbvXG3SvzArR44
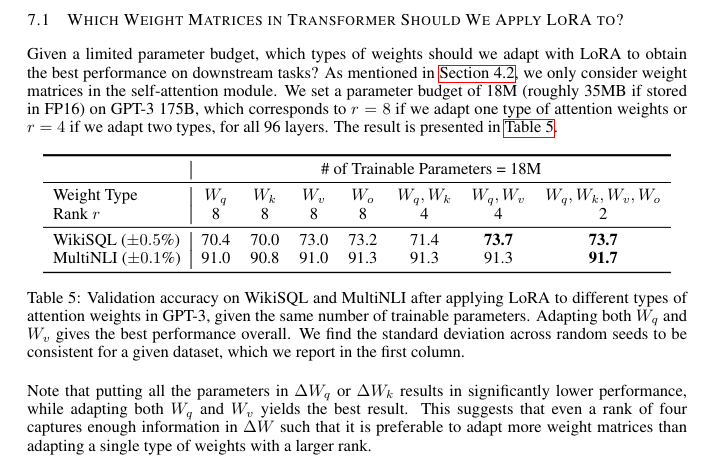
in the original LoRA paper, they have a dedicated paragraph about “okay what settings should you use” (fig. 1), you can get quite a lot out of it by just tuning on more parts of the model, even with lower rank settings
now, on the QLoRA paper, i don’t find a proper mention of which layers are used, probably because their goal is “run lora but add some stuff to make it stable on 4-bit”
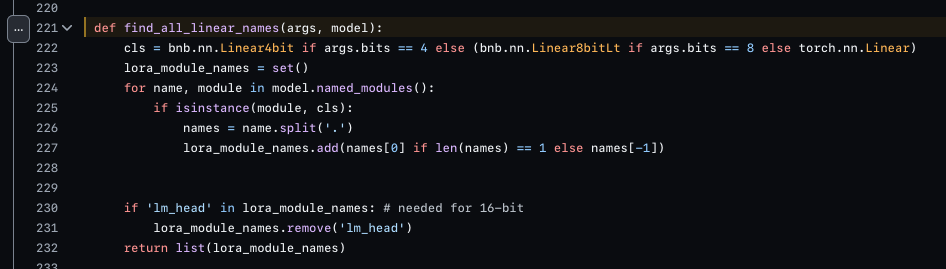
so i peeked at the code, and i find this (fig. 2)
so their answer is to just… use all the layers they can get their hands on??? lmao????????
https://f.l4.pm/notice/AXrtqUUqQpGNRMdqZk
found the reason on Tim Dettmers’ talk on QLoRA from 2wks ago
T+29:30 explains the hyperparameters that matter and he elaborates that LoRA only applies to the attention modules of the network (that’s correct), but that didn’t work on qlora experiments. all layers are required to make it actually perform
which answers the question of “why doesnt qlora provide layer configuration like usual lora does”
nice