The Architecture
#author_luna #spam #artificial_intelligence #large_language_models
this is a copy-paste of a long thread i wrote up on fedi mid december 2023. thought it had enough power to be its own article
the more i look at spam the more i look at The Architecture i cooked up in july
not sure what to do about that feeling
gitdab.com is a spam target, neither of us can keep up with it because we have things to do and places to be
we attempted recaptcha, and hcaptcha, both can be just paid for.
the solution is slowly becoming "close off all public registrations, use friend-of-friend (somehow) to let people through". lobste.rs does this, a3.pm does this, elixi.re does this
even then, friend-of-friend is heavily manual unless the software is made for it, and most software isn't (a3.pm and elixi.re are manual)
what to do, then?
fedi is a whole different beast, all that i said only apply to centralized platforms. fedi is not centralized and a spammer or bad actor requires hashtags like fediblock and word of mouth from people to people to get them shutdown from the network. this is not scalable, but you could argue that's a property of fedi that you can't remove.
email has spam issues, that has to be an automated filter. it's how we only got like 3 main email providers, a bunch of small scale ones, and you are reputation'd out if you try to start on the system with your own ip
fedi has small scale spam issues, of whose filtering is not automated yet, but what happens in the future where threads dot net goes widespread? more eyes on the network, more people, more spam targets.
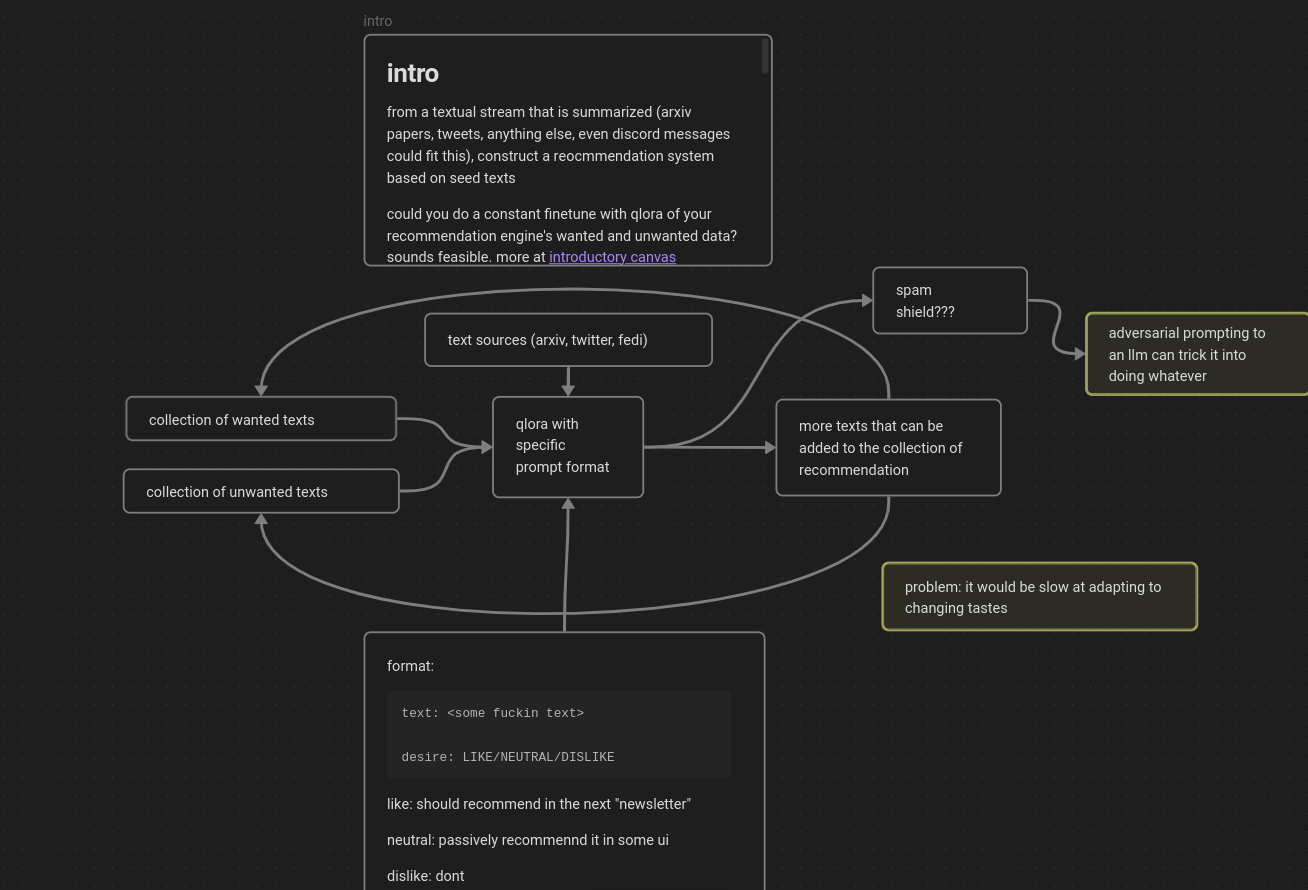
it's sort of why i look at The Architecture (mentioned above). automated individual filtering system for massive information flows. the first application is arxiv papers, but you could generalize to any low signal-to-noise ratio flow
here's another "anti-spam" measure that doesn't work nowadays: i just got another spam/phishing scheme on whatsapp.
y'know, the messaging app that requires you to have a phone number, to prove you're a real entity. what am i supposed to do? report as spam, and wait for the next phone number to appear on my phone.
at this rate, i don't think any "proof of humanity" system (hcaptcha, recaptcha, privacy pass, worldcoin), or manual moderation system, can work in an increasing spam-ful future that spreads beyond email (fedi, whatsapp, discord*, youtube).
- (discord is, afaik, mixed system, there's manual review and automated systems that keep spam in check)
in a way, twitter's move to lock all dms for premium users only on its spampocalypse was the option they had to make, because scaling up the moderation team would've been an increasing battle of costs between attack and defense, and its likely twitter was not profitable back then (and likely still isn't yet, elon is trying hard tho, and likely succeeding)
you can't even waste these people's time anymore like it was with a proper phone call. it's all over text, they have preconfigured response trees for the attack
on an earlier subthread, i wrote more things about The Architecture, here are they and some more, condensed into the main thread:
- adversarial inputs. people can optimize and learn ways to defeat the filter, that's why proprietary spam filters remain proprietary. if someone learns enough about you they could provide content that is already aligned yet is still spam, defeating the system
- it could be made with today's language models
- integration is... a weird problem. you likely want to attach the filter at the layout level of the system to provide filtering that doesn't break the design of the content, which leaves us with two attachment points:
- the browser (something like ublock origin), or
- the graphics server (x11, wayland, etc)
- if you use today's models, you need something that can filter in the background for you, before rendering the content to the screen, because they're an order of magnitude slower than how fast the text can be shown to your eyes
- you could optimize models to low million parameter sizes (shoutout to maxine), that would be very fun research to go with
- if you want to go below the browser's layout engine, you get two other attachments:
- filtering the specific content being layout'ed on your machine, if you attach here you need support for every information stream on the planet (twitter, fb, youtube, mastodon, pleromafe, akkomafe, etc, etc, you get the deal)
- the server giving the content, and running ai models is costly at scale. prefer to run it on-device
- above the graphics server is the framebuffer, attaching here would require an OCR system and a fast model that won't be able to filter content that "may be rendered in the future" (anything paginated). it would be something really fast is my guess
- phones? right, phones. maybe you could do something by attaching to the Accessibility system as those should provide a lot of tweaks to how the system can work, without root.
- would also apply to Mac or Windows, as you can't attach to their graphics server as freely as you could on x11.
- browser plugin is probably the best one to attach to for starters but we would need a proper system that can be generalized to any runtime, not just the browser (qt, gtk, apps on game engines like godot/unity, etc)