understanding anime taggers
+++
date = "2023-06-10"
+++
#artificial_intelligence #tagging #author_luna #ai_research
i clearly know how numbers work.
UPDATE
UPDATE
i found out about the deepdanbooru project some 1~2 years ago, and used it in conjunction to my hydrus-esque indexing system to tag media that couldn't be tagged manually or automatically with the Danbooru API. the model receives an image, and gives out a list of tags with the respective confidence the model has for each tag. my pipeline cuts off at a certain confidence threshold (at the moment, 0.7), and submits that for indexing.
the AI boom of late-2022 with Stable Diffusion and NovelAI Diffusion led to a bunch of attention and respective work being done in the field of AI imagery, such as the leaking of NovelAI Diffusion's weights and the work being done to integrate it in stable-diffusion-webui brought my own attention into the AI space, as someone else puts it:
Given today’s leak of the NovelAI models, I find it pretty funny that after all the academic work on elaborate “model stealing” attacks, real world model stealing is more like “someone put our model weights on a torrent site”
- Brendan Dolan-Gavitt (moyix), 2022-10-07T00:30:10+00:00
the Waifu Diffusion effort appeared with a goal to be a "reproduction" of NovelAI Diffusion done purely in the open, many models were released under that effort, the latest releases being 1.4 Anime, and 1.5 Beta 3
for that training effort they needed a giant dataset, and while Danbooru (thanks to Danbooru2021) can provide a lot of data, anime art hubs exist that don't provide rich tagging, like pixiv, so a clear need was to synthetize tagging from images that didn't have them, and that's where the tagger models by SmilingWolf come in.
i haven't looked at the models until i had to use a a stable-diffusion-webui extension to do my own experiment training runs on my RTX3060. that's when i got first contact with these models
fast forward some months, and i had the great question of "how does deepdanbooru compare against smilingwolf's models?", possibly to replace them, as the latest DeepDanbooru model is from late 2021
i think this is the first mention of the smilingwolf models by themselves, from a pre-waifu-diffusion-1.4 era, i have no idea how the timeline actually goes here. most interesting part is this
More networks! Model zoo! Point is, I'd like to find out how well new archs, bigger archs, mobile archs work outside of Imagenet. RegNets, for example, were an utter disappointment
and yeah they did make a model zoo, also see "What is Waifu Diffison 1.4 Tagger?" by toriato
another part of that reddit post is this one
using a set of images from ID 4970000 to 5000000 as validation and an intersection set of tags common to both my training data and DeepDanbooru's, resulting in 2199 different classes tested on 28995 images for a total of 811739 tags, my network obtains about 3.2% better F1 score at the intersection between P-R curves.
i do not understand it at all. i don't have a degree in this stuff, yet i wanted to create a way to systematically compare model performances, and that's where tagger-showdown comes in
the statistics shown here are to be taken with a giant grain of salt. i had to make some hacks to the DeepDanbooru model to have its tags aligned with Danbooru, for example.
methodology #
scoring #
i wanted to score the models with three criteria in mind
- reward amount of tags that are in the danbooru ground truth
- punish amount of tags that are not in the danbooru ground truth
- must be normalized on 0-1 range
that was one of the first parts of the project, as you can't do anything else without that.
the formula is as follows, shown in python pseudocode:
len(tags in danbooru) - len(tags not in danbooru) / len(danbooru tags)
here is the code for the scoring function
dataset #
i wrote a quick script that would download the latest images off danbooru, with their respective post metadata into a data.db sqlite file
for this scoring run, i downloaded approximately 50 images from each Danbooru rating category (general, sensitive, quesiontable, explicit), with a page skip of 150 (as new images given to danbooru are not good "ground truths" to their respective tagging, it might take a while for the moderators and/or taggers to come back to it and finish the work) (thanks dither for suggesting this midway through, as that helped to remove a lot of outliers)
getting the tagger models #
wd14-* family of models are from https://huggingface.co/SmilingWolf, runnning inside toriato's sd-webui extension, which provides an API that i can use in my scripts!
deepdanbooru model running inside the hydrus-dd integration, of whose model is https://koto.reisen/model.h5, in theory i could've used the latest snapshot from the github as well, but i already packaged model.h5 into my pipeline.
running the tagger models #
i have two systems:
- my laptop: intel i5 1035g1, nvidia mx350, 20GB ram
- my desktop: amd ryzen 5 4600g, rtx3060, 32GB ram
the wd14 models ran on my desktop, which means they had the full power of my gpu.
the deepdanbooru model ran on my laptop, on pure-CPU mode. this renders an "universal" comparison of runtime useless, and that's fine. i wanted to answer if the wd14 models could be a part of my pipeline, with the drawback being that i needed my desktop running to get access to them.
the numbers! #
please make sure you've read the methodology, as these results should have a grain of salt taken on them.
| model | avg score | avg runtime |
|---|---|---|
| wd14-vit-v2-git | 0.202 | 0.915 |
| wd14-swinv2-v2-git | 0.200 | 0.924 |
| wd14-convnextv2-v2-git | 0.195 | 1.007 |
| wd14-convnext-v2-git | 0.186 | 0.878 |
| wd14-vit | 0.184 | 0.935 |
| wd14-convnext | 0.169 | 0.872 |
| hydrus-dd_model.h5_0c0b84c2436489eda29ccc9ee4827b48 | 0.093 | 1.865 |
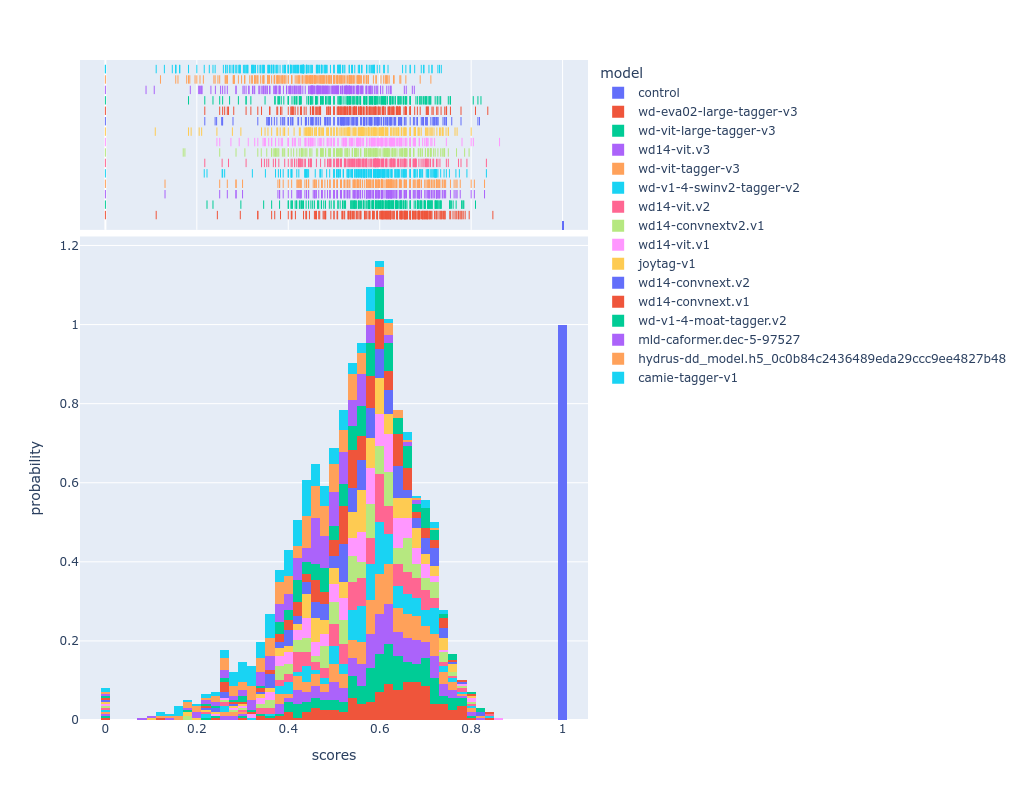
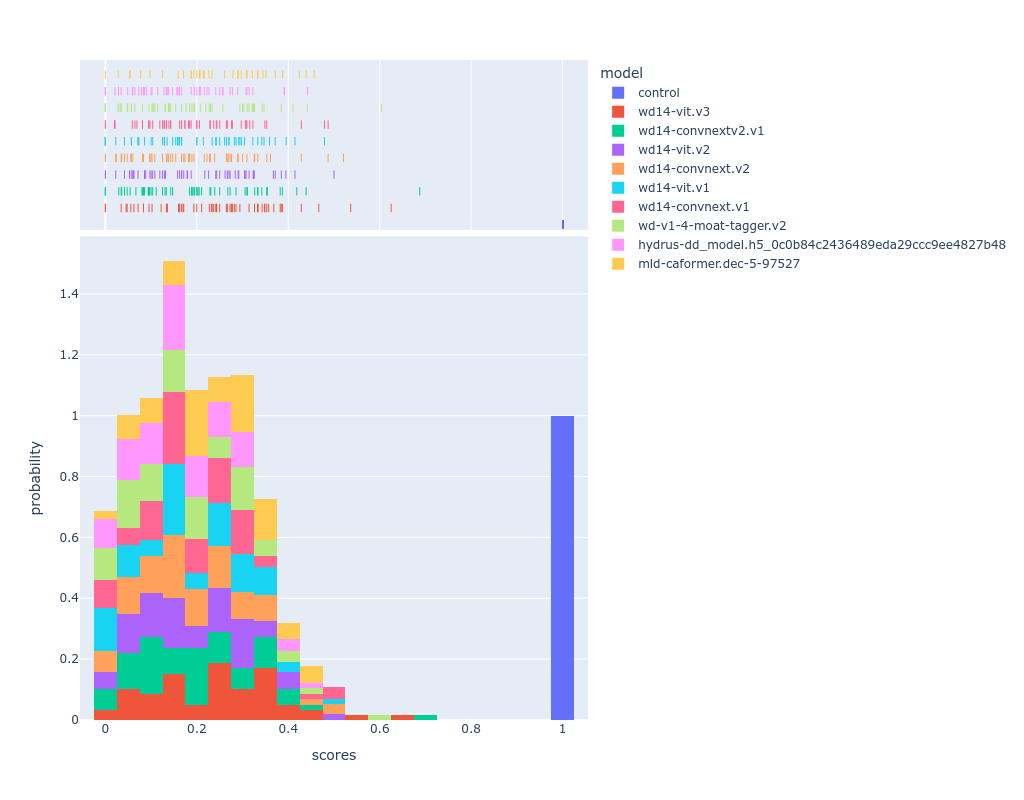
here's the score distribution across these models, as you can see the deepdanbooru model ranks poorly because it's consistent on the low end of the score spectrum.
the "control" model is a mock model that replies with the original danbooru tags for that post, it was made to assert that my scoring calculations are correct and that it'd receive a score of 1.0 always (as you can see in the histogram, it does)

as there's outliers on the negative score range, i made a cutoff point at 0 to show the distribution with more pixels.

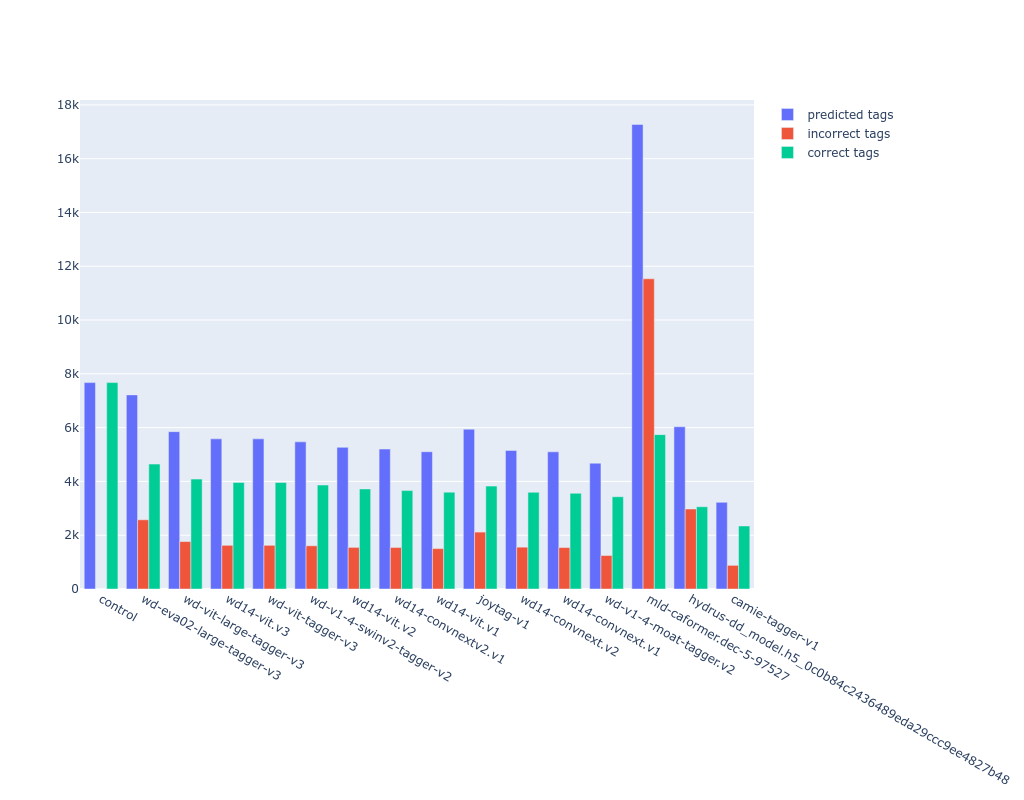
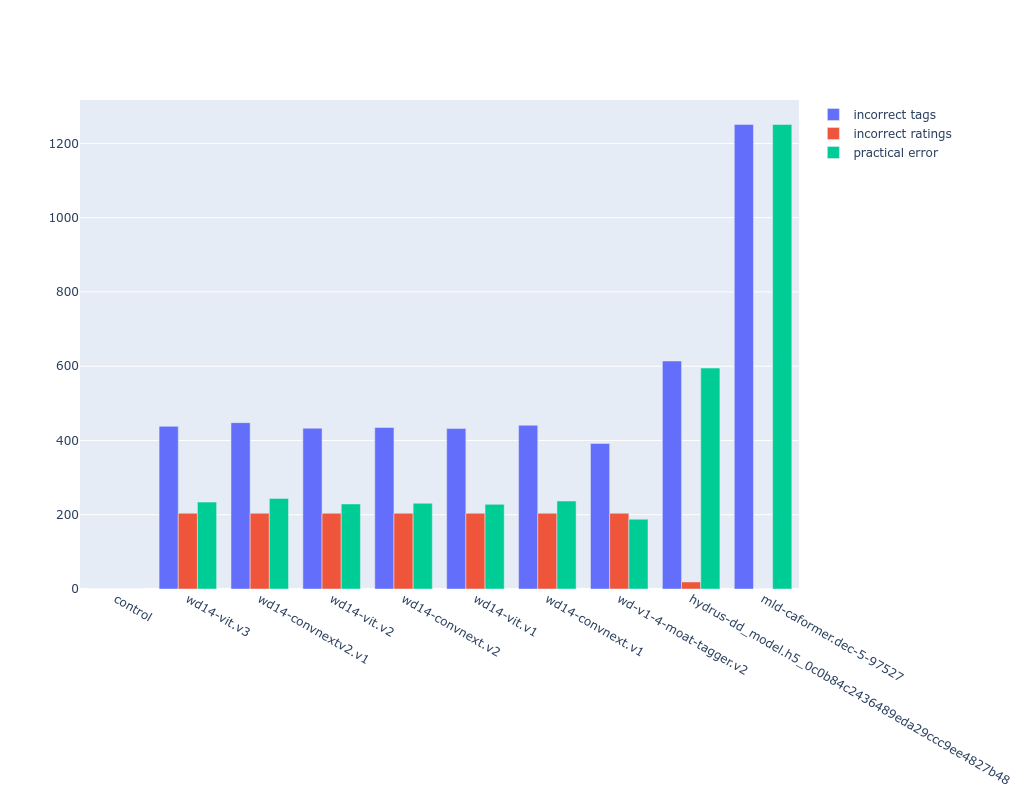
also i wanted to show the error rate of the models (the len(tags not in danbooru) number in scoring). the wd14 models more consistently get content ratings wrong compared to deepdanbooru. in turn, the "practical" error rate (green column) of these models is (incorrect tags - incorrect ratings), which shows smilingwolf's models as being approximately 50% better than deepdanbooru. this result makes sense considering the average score

conclusions #
- wd14 models good
- might use them in my tagging pipelines
- most likely will use the
wd14-vit-v2-gitvariation as that's what scored the best out of all of them - i am not good at statistics. take everything i'm saying with a grain of salt
- from toriato's notes, the swinv2 model allegedly runs slower, but i couldn't reproduce this finding.
- the note about swinv2 being better might be actually correct, swinv2 vs vit gives a
0.002score difference, which is margin of error at this scale.
- the note about swinv2 being better might be actually correct, swinv2 vs vit gives a
future research questions #
probably for someone else to do, i got the answers i wanted
scoring functions #
suggested by emma while proof-reading:
does make me wonder about like
tag distance
and taking that into account when scoring correctness
i.e. there are probably tags that mean similar things that are not the same tags that might be considered more correct than a tag that has nothing to do with the tags on the ground truth
and you could maybe get some sense of that just from what tags tend to appear together? but that wouldn't be based in any lexical understanding of the tags
maybe score could be (sum of distances of predicted tags to actual tags)
i'm not super interested in continuing, but i think this would involve some sort of multimodal model that can take an image, its tag description, and do some sort of computation on top, maybe LLaVA could do something like it? i'm not sure.
2024-08 numbers #
model updates:
- remove wd14-swinv2-v1, it brokey
- not same image testing dataset as previous run, fresh ~200 images from danbooru
- add wd-vit-tagger-v3 via https://github.com/neggles/wdv3-timm
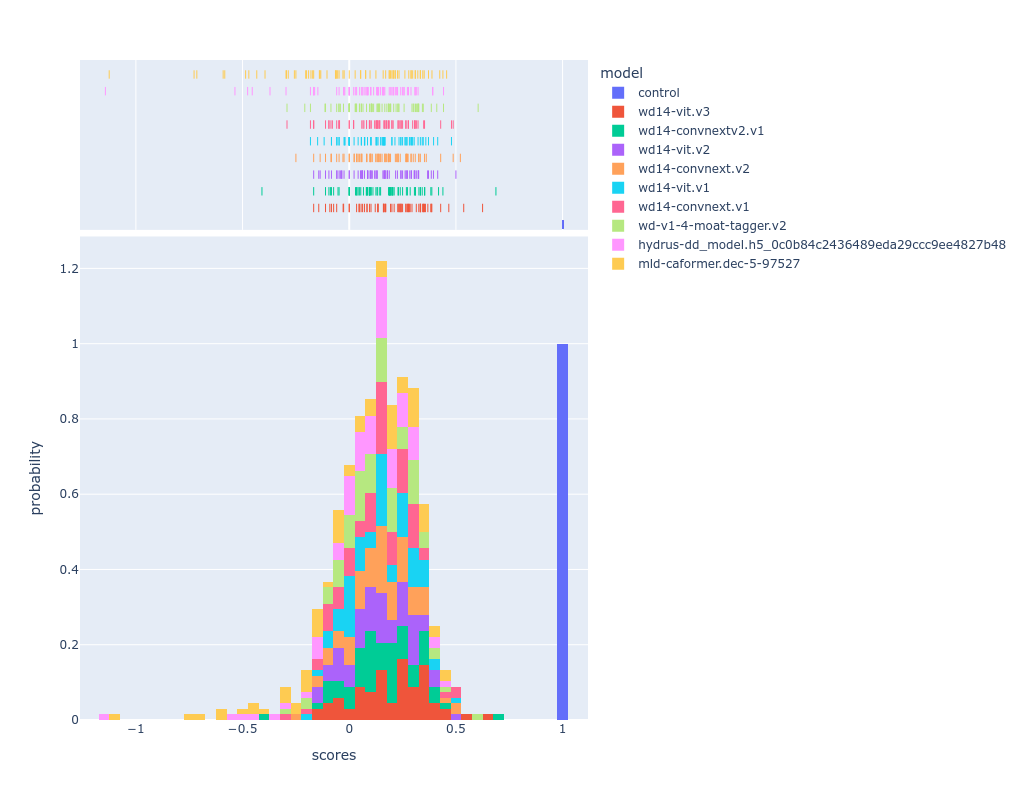
- vit v3 is the best tagger out of the existing ones, and is what i'm going to roll with moving forward (i was using swinv2-v1)
| model | score | avg runtime (seconds) |
|---|---|---|
| wd14-vit.v3 | 0.192 | 0.28 |
| wd14-convnextv2.v1 | 0.148 | 0.31 |
| wd14-vit.v2 | 0.144 | 0.18 |
| wd14-convnext.v2 | 0.144 | 0.30 |
| wd14-vit.v1 | 0.139 | 0.18 |
| wd14-convnext.v1 | 0.132 | 0.31 |
| wd-v1-4-moat-tagger.v2 | 0.130 | 0.36 |
| hydrus-dd_model.h5_0c0b84c2436489eda29ccc9ee4827b48 | 0.064 | 0.74 |
| mld-caformer.dec-5-97527 | -0.00 | 1.50 |
2025-04 numbers #
updates:
- IMPORTANT NOTE: these results are not vetted by my current employer. i do not work on the models nor dataset. i worked on this in my free time.
- not same image testing dataset as previous run, fresh ~200 images from danbooru at varying rating levels and time spans
- trying my best to keep the scoring set updated so that the probability of score hacking by model trainers is low.
- add camie-tagger-v1 (via camie-tagger-onnxruntime)
- i spent hours trying to mixmatch the proper onnxruntime version with cuda, reverse engineering its own
setup.py(which is low quality slop mind you!!!!!!! its not even a setuptools-style thing, it sets up the venv itself and calls pip via subprocess itself. yeah i'm not going to do that) - i seriously do not like how camie-tagger's own readme feels like completely written by an llm, as well as the... tagging game...?? feature??? i really just want the model and preferably an api to infer it. you cant be more direct than that. very exhausting
- i spent hours trying to mixmatch the proper onnxruntime version with cuda, reverse engineering its own
- add joytag-v1
- add https://huggingface.co/SmilingWolf/wd-vit-tagger-v3
- add https://huggingface.co/SmilingWolf/wd-v1-4-swinv2-tagger-v2
- add https://huggingface.co/SmilingWolf/wd-vit-large-tagger-v3
- add https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
- thankfully all of these are compatible with wdv3-timm
- move thresholds from 0.7 to 0.5, vibe-based decision. camie and joytag didnt give a lot of results at high thresholds which might muddy the results, plus i already use 0.6 internally
- remove rating and artist tags from scoring (only keeping general, character, copyright)
- automated rating and artist tags are effectively useless for my purposes
- models get rating wrong all the fucking time. at this rate it's easier to just create a dedicated rating classifier model directly (see the previous results from 2024-08, out of all incorrect tags on vit-v3 which was the best model from that run, half were just incorrect ratings...)
- most of these models do not even give out artist tags (camie-tagger does methinks???)
- there's no proper agreement on rating syntax, requiring postprocessing
- using f1 score instead of whatever i cooked back then. dont let me cook.
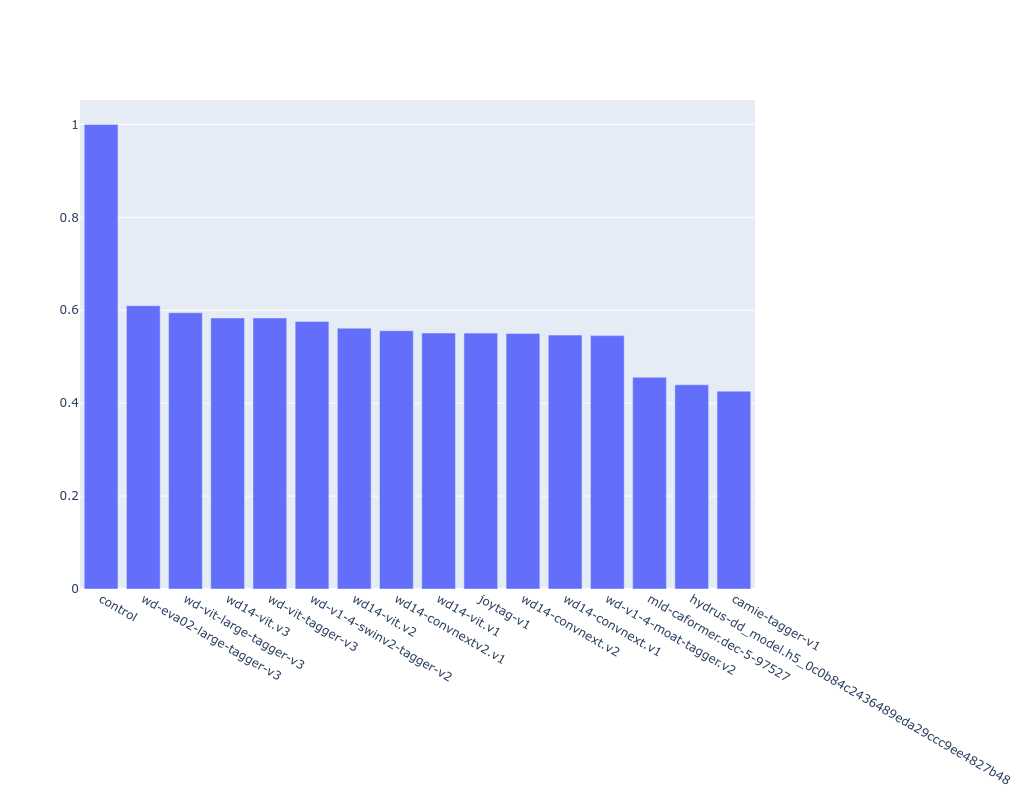
- conclusion: wd-eva02-large-tagger-v3 seems to be the best one
- it is a tad bit slower than my previous go-to tagging model (wd-vit-tagger-v3), but not that slower. seems to give good results as well
- i kinda wanted camie-tagger to win. keep in mind it provides much more thorough benchmarking scores (like micro f1 and macro f1) but i can't trust the random numbers that i don't understand. i simply download the danbooru and run the number i do understand
| model | score | avg. runtime (ms) |
|---|---|---|
| control | 1.000 | 0.0 |
| wd-eva02-large-tagger-v3 | 0.610 | 0.69 |
| wd-vit-large-tagger-v3 | 0.595 | 0.65 |
| wd14-vit.v3 | 0.583 | 0.46 |
| wd-vit-tagger-v3 | 0.583 | 0.46 |
| wd-v1-4-swinv2-tagger-v2 | 0.576 | 0.47 |
| wd14-vit.v2 | 0.562 | 0.38 |
| wd14-convnextv2.v1 | 0.556 | 0.47 |
| wd14-vit.v1 | 0.551 | 0.39 |
| joytag-v1 | 0.551 | 0.37 |
| wd14-convnext.v2 | 0.550 | 0.45 |
| wd14-convnext.v1 | 0.547 | 0.44 |
| wd-v1-4-moat-tagger.v2 | 0.545 | 0.5 |
| mld-caformer.dec-5-97527 | 0.456 | 1.83 |
| hydrus-dd_model.h5_0c0b84c2436489eda29ccc9ee4827b48 | 0.440 | 1.39 |
| camie-tagger-v1 | 0.426 | 0.3 |