the Donut algorithm

#author_luna #bluesky #atproto #recommendation_algorithms
this is an article related to nagare, my general-purpose bluesky feed side-project. previously described in discover feed fever dream. in this article I talk about what I've been working in the past month, which is trying to solve the "low following" problem. from the previous article:

in this graph, i plot the amount of follows a user has, and the amount of problems they're seeing in their basic likes-from-follows feed. at the low end of the spectrum (10 to 100 followers), the problems they see are shaped as "not enough activity, feed becomes stale", but at the higher follow counts like 1000+ are differently shaped problems, mostly related to having so much activity i don't think i would be able to hold storage for that type of tester.
I was able to find a solution to the "high following" problem and got two testers that can validate the feed's effectiveness. I myself am on the "low following" part of the graph (as well as some others) so I want to find systems that can target both groups and bring them down to the "center" of the graph.
for high following accounts (as in, they follow a bunch of people) it was "simple":
- find some ranking function that represents some relationship that provides itself to be "useful" for this purpose between two users
- order the accounts they follow by this function
- top ~400 become "the actual follow set" (since that was my ARBRITARY(!!) threshold for testers)
- then run likes-from-follows as normal
the specifics of the function are related to how various parts of nagare do scoring (for posts, specifically), so going too deep into that wouldn't work for others (especially because those models aren't even finished), but the main idea is:
- for the main scoring function, model the following signals:
- the author of a post
- the user that liked a post (since the feed heavily relies on likes for recommending posts)
- the words of a post (normalized! lowercase it all and remove stop words)
- build/"train" the model from the main user (feed user)'s top 100 likes
- then go through each user that is followed, grab their last 5 posts
- infer the scoring model on each followed user's post
- average on the 5 posts, you get a single number
- sort!
the low following problem #
genuine brainworms on it. I have multiple notes, some made in VR, many more made in my notebook, on how to solve and implement this. at the core of all these ideas is building something that can extrapolate the "aware social graph" from what a given user likes. in general what I've seen from Twitter's algorithmic behavior is that even a singular like spawns quite "drastic" changes to how the feed personalization is done, and I wanted to implement that because just treating "likes-from-follows" as-is is not enough (as shown in the graph above!)
various ideas, in somewhat order of "idea had":
- virtual follows
- somehow decide specific user X, Y, Z now is a part of your feed, all their posts go to your feed directly without any filter
- this was a disaster. since there's no filter the user feeds were overrun with posts from the virtual follows, requiring me to do some deep refactoring to separate "likes from follows" and "virtual follows" as two separate feed sources so I could axe the separate system (and then create new feed source systems! which is how the new Donut system, explained here, is integrated)
- "minicluster"
- build embeddings from what the user likes
- build "anti-embeddings" from what the user dislikes (via reports)
- represent "miniclusters" of subjects with
(embedding, min_cosine_distance, max_cosine_distance) - ...then do what? i didn't go beyond that. the idea quite literally stopped there becaust I didn't understand how to build those clusters, update them over time, and plug them as a feed source
- "subcommunity detection"
- I don't have a lot written on it so I just forgor :skull:
- "spidercluster"
- from a singular like, go through the post author's likes and then keep going until some fixed distance (say, 2 or 3)
- somehow build up clusters from that data based on interactions (say, automatically find the "vrchat creator" cluster)
- ...then do what? interaction with the existing feed system was also kind of left as a blank
and then kara joined the tester group and heard of my woes. the last one, "spidercluster", is the one that I got the most progress on, even downloading data and being able to plot out... something that looks like a clustering algorithm on it (NOTE: this screenshot is from experimental work):
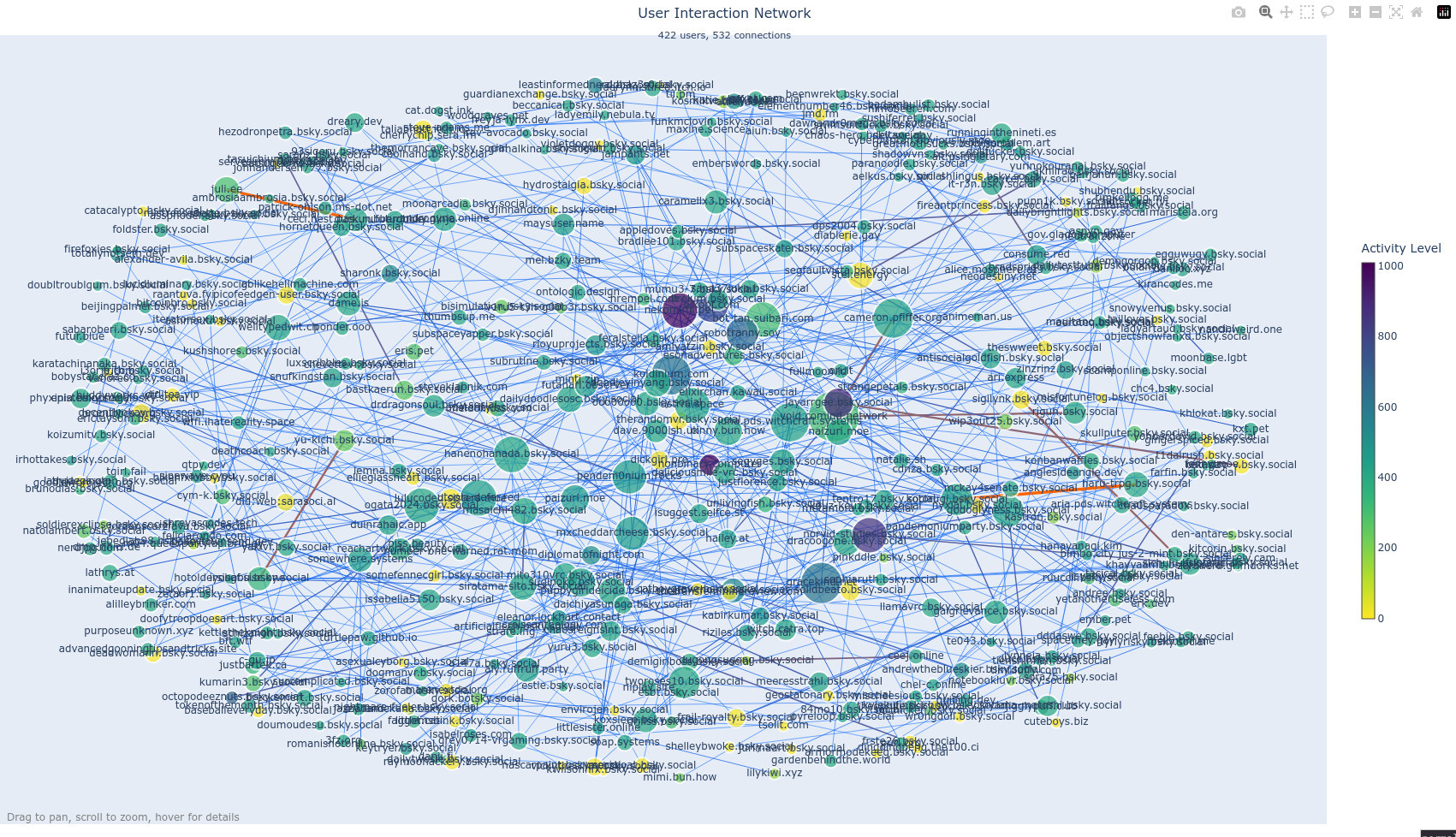
upon hearing my woes, his words were
my intuition (read:unsubstantiated guess) is that you'd get good results from sampling a cluster from the outside, under the assumptions that:
- creators are no more likely to follow similar creators as they are arbitrary other people (low internal connectivity)
- people who like the same types of posts are likely to be similar in other ways (high inbound connections)
- more people are liking posts than making new posts (also high inbound connections)
so you'd get small clusters of creators who may or may not engage with each other, surrounded by a large ring of similar people who like those creators "frequently"
idk how your graphs are built so I can't make something up for those, but for this (in case it's similar) would probably be something like this:
when feed user likes post: // identifying cluster via sampling create a histogram get users for all likes of post for each user: get latest N likes add authors of those posts to histogram select top P% users from histogram // post selection from cluster, do what you want, just making something up select latest M posts from each shuffle those into the feed
after a couple of days he got a proof of concept working: see source here and I saw that something there worked so I proceeded to implement that into the nagare codebase.
I expect the graph to look basically like this, ideally (lines are likes)
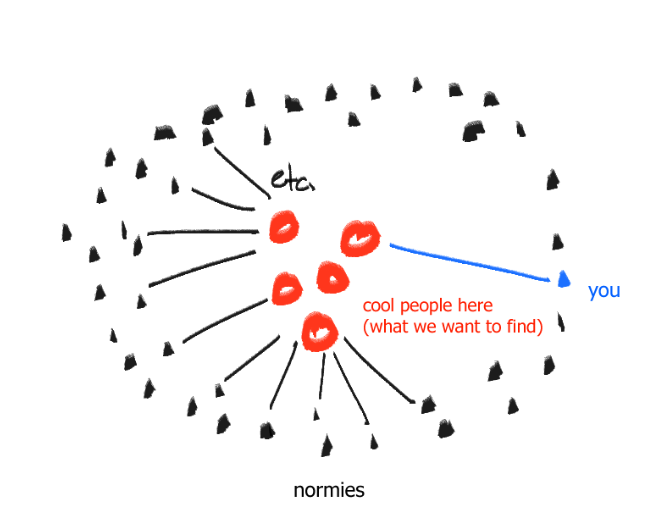
and since that diagram kind of looks like a donut with the outer ring being everyone that likes stuff, the Donut Algorithm was properly titled and created.
The Donut Algorithm #
at a high level, this is how it works. from a given seed user did (the feed user is the seed user in my case, but I could run this on other seed users):
- scrape their last 100 interactions (likes OR reposts, whichever fills 100 first. prefer likes). this is done via the
listRecordsXRPC which is something I've talked on the previous article - from those interactions, use microcosm's constellation (extremely cool by the way!) to find (20) co-interactors (for now, I just use co-likers but I could use co-reposters in some future day)
- for each of the co-interactors, fetch their last 20 interactions (this can be done by resolving their PDS and then
listRecords) - at MOST, you will have 40K records in total after finishing scraping
- from that set of data, compute two sets:
- which users were liked the most (this can be changed to some other function that carries different information to sort users by), I call this "candidate authors"
- who serves as a "filter" for those users. this is somewhat more specific to how nagare works, but I'll elaborate later. I call this "candidate likers"
it feels simple in description, but its implementation took weeks. the main problem with this algorithm as-is is that I need to make it realtime aware! users change their tastes over time, like different things, which means the candidate user sets that the algorithm finishes with may change over time and I would prefer to not continuously scrape various servers every time one of my testers like something. for this purpose there's the firehose which I can attach to after scraping, but that adds another issue which relates to the previous article: storage use.
the feed runs on a tiny VPS. it doesn't have a lot of storage (but I want to migrate to another VPS, the problem remains though). that means I need my system to be aware of which data to evict away from the database over time (I'm intentionally not scraping all seed user interactions, or scraping more than 20 per co-interactor. I want to also be aware of their tastes changing over time). to make a storage layer for this that works in causing fast evictions of data is a problem that I have multiple pages on my notebook for.
the solution I've landed on for this was reference counting (refcounting). in the schema for the system that runs the donut algorithm, I have something like this:
CREATE TABLE IF NOT EXISTS "records" ( "at_uri" TEXT NOT NULL PRIMARY KEY, "did" TEXT NOT NULL, "collection" TEXT NOT NULL, -- app.bsky.feed.like, app.bsky.feed.post, etc... "rkey" TEXT NOT NULL, "data" TEXT NOT NULL, "created_at" INTEGER, "record_type" TEXT ); CREATE UNIQUE INDEX "records_did_collection_rkey_index" ON "records" ("did", "collection", "rkey"); -- reference counting. FROM at_uri TO ref_uri (at_uri->ref_uri) CREATE TABLE IF NOT EXISTS "record_refs" ( "at_uri" TEXT NOT NULL, "ref_uri" TEXT NOT NULL, PRIMARY KEY ("at_uri","ref_uri") ); -- keep track of what or who i've scraped CREATE TABLE IF NOT EXISTS "scrape_state" ( "scrape_type" TEXT, -- "user" (on pds) or "post" (on constellation) "entity" TEXT, -- did:... or at:// "scraped_at" INTEGER NOT NULL, PRIMARY KEY ("scrape_type","entity") );
as I scrape records, they get different record_types:
- L1: represents the feed user's likes
- since they're from the user, their refcount is fixed at 1, and are the "start" of how deletions work (explained later)
- P1: represents the posts the feed user is liking
- likes on bluesky are very small and just contain a reference to a post. it's required for me to scrape the post itself
- and I need to scrape the post so that I can filter users liking posts that reply to themselves, because that's not really representative of something the a user truly liked, but it is more aligned with social ettiquette.
- 1 L1 record references 1 P1 record
- L2: represents other people's likes to the same posts
- done by scraping constellation with the "P1"
- 1 P1 references up to 20 L2 records
- U1: represents the users who are liking the same posts as the feed user, e.g. the people doing the L2 liking
- up-to-20 L2 records reference a single U1
- L3: represents what else those U1 users like, which we use to determine the candidate authors and candidate likers
- single "U1" references up-to-20 L3 records
this is done because, since I keep top-100 likes from the seed user, once a new L1 record (a like from the seed user) comes, I want to evict the oldest one and have a guarantee that the entire chain dependent on that oldest L1 gets deleted too! there has to be a clear path from "L1 gets deleted" to "L3 gets deleted if there's no references anymore" and I don't want a solution that would require me to load the entire graph in-memory to then know what I need to remove, because the VPS only has 4GB of ram! (there are other services on that VPS!). here's what the "reference" graph looks like:

I took three different shots at implementing something that works and each time I did it I had various bugs, most of them are data consistency issues (say, U1 references L2 which should not be possible) which over time would cause data degradation (deleting too much) and so the sets of users would simply break.
(sidenote: you may think that since likes reference posts, it should be modeled as L2->P1 rather than P1->L2. this is not done because the reference direction represents "data dependency from the feed user". doing it in the other way around would involve creating special-cases for how P1 deletions are handled. keeping everything in a singular direction forward simplifies code)
integration #
from the first idea shown at the start of the article, the "virtual follows" system was not very good in terms of expanding follow sets, but the Donut algorithm could provide something akin to virtual follows by instead turning it into "likes-from-virtual-follows". given the candidate likers, they become filters for the posts made by the specific authors, guaranteeing that there was "social proof" that a specific post can be recommended instead of just everything-all-at-once.
once the two sets are made (and you can resync the sets every time the seed user likes, though at least in my implementation I need to keep track of everyone for their L3 records) I can send them over to another system whose job is to keep track of those likes. it's not true "likes-from-virtual-follows" because I'm not choosing to go with all of their likes, only the ones that were made to the candidate authors set.
did it work? #
for the most part, tester reception has been okay (subjectively). part of my work was also adding A/B testing capabilities so testers can feel what the new system does and if they prefer it compared to pure likes-from-follows. it wasn't an unanimous dislike (like it was with the first iteration of virtual follows), which is progress to me!
there's various other things to work in before finalizing it, but I'm happy with it overall and I probably should refactor it for a fourth time because I think I still have some data consistency bugs. areas of improvement:
- scrape "P2" records
- turns out it's not just seed users liking replies to their own posts, but also the "U1" users too, I dub it "the bot-tan problem", bless its soul but recommending bot-tan replies to users is low signal sadly
- tweak how the feed attempts to decrease "reader stamina exaustion"
- say, someone sees 3 posts from the same person in rapid succession (because the authorship of a post is quite a strong signal in my post score model)
- having that go over and over for various other users kills reader stamina
- depending on the type of poster (no callout this time) you can reach those "failure modes" of how the feed works
- I would prefer if users enjoyed using the feed. so I'll have to find a better way to prevent the feed from getting stale
- better post scoring model
- it's easy to reward hack (requiring things like social proofs from likes into the entire system) with hashtags or just words in general. posts with more words get scored higher!
- it's hard to represent concepts someone dislikes with it (it does work on downranking users, but it can't reliably model "likes user's posts but only in specific subjects")
- the model starts with just your top 100 likes, but keeps storing more likes continuously instead of evicting old likes. this contributes to the model becoming "stale" over time, etc
- this is the part where philpax begs for me to run an embedding model on the entire world. then use cosine similarity. I can't dedicate GPUs to run embedding models, but there could be something to be done here.
- add show more / show less integration!
- less than a week ago, gracekind.net's pull request to bluesky was merged, adding support for the "Show More" and "Show Less" buttons to be shown on all feeds. previously, only the "blessed" feeds like the bluesky discover feed had it.
- this causes two important UX things for me:
- I can remove the "report ux hack" (see previous article: discover feed fever dream) used to represent "show less" in my system
- liking feed content can now be a private interaction between user and feed. I had to rely on likes otherwise
- I can (and am trying to! I applied
acceptsInteractionsbut the appview hasn't updated the feed ui...) add support for it, it's not trivial because "show more" only happens in the context of a feed. it's more differently shaped than a like (plus, likes are one click).- in the case of "show less" though, that's an interaction that took 5 clicks with the report UI, now down to 2 clicks. I should implement this asap
- there's much more
at the end, a good general-purpose feed is hard. absurdly hard. each single issue or featire spawns more issues or features in a fractal of Things that a feed should be aware of. a feed's interface is simple, just get some posts and give them to the user, right? right????